
JAVA多线程:
进程和线程:
进程:每个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销,一个进程包含1–n个线程。(进程是资源分配的最小单位)
线程:同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。(线程是cpu调度的最小单位)
线程和进程一样分为五个阶段:创建、就绪、运行、阻塞、终止。
多进程是指操作系统能同时运行多个任务(程序)。
多线程是指在同一程序中有多个顺序流在执行。
在java中要想实现多线程,有两种手段,一种是继续**Thread类,另外一种是实现Runable接口.(其实准确来讲,应该有三种,还有一种是实现Callable接口。
1 | package com.multithread.learning; |
说明:
程序启动运行main时候,java虚拟机启动一个进程,主线程main在main()调用时候被创建。随着调用Thread1的两个对象的start方法,另外两个线程也启动了,这样,整个应用就在多线程下运行。
注意:start()方法的调用后并不是立即执行多线程代码,而是使得该线程变为可运行态(Runnable),什么时候运行是由操作系统决定的。
从程序运行的结果可以发现,多线程程序是乱序执行。因此,只有乱序执行的代码才有必要设计为多线程。
Thread.sleep()方法调用目的是不让当前线程独自霸占该进程所获取的CPU资源,以留出一定时间给其他线程执行的机会。
实际上所有的多线程代码执行顺序都是不确定的,每次执行的结果都是随机的。
但是start方法重复调用的话,会出现java.lang.IllegalThreadStateException异常。
实现Runnable接口:
1 | package com.multithread.runnable; |
说明:
Thread2类通过实现Runnable接口,使得该类有了多线程类的特征。run()方法是多线程程序的一个约定。所有的多线程代码都在run方法里面。Thread类实际上也是实现了Runnable接口的类。
在启动的多线程的时候,需要先通过Thread类的构造方法Thread(Runnable target) 构造出对象,然后调用Thread对象的start()方法来运行多线程代码。
实际上所有的多线程代码都是通过运行Thread的start()方法来运行的。因此,不管是扩展Thread类还是实现Runnable接口来实现多线程,最终还是通过Thread的对象的API来控制线程的,熟悉Thread类的API是进行多线程编程的基础。
Thread和Runnable的区别
Callable接口与Runnable接口相比,只是Callable接口可以返回值而已。
如果一个类继承Thread,则不适合资源共享。但是如果实现了Runable接口的话,则很容易的实现资源共享。
总结:
实现Runnable接口比继承Thread类所具有的优势:
1):适合多个相同的程序代码的线程去处理同一个资源
一个任务可以启动多个线程
2):可以避免java中的单继承的限制
实现了一个接口,同时还可以在继承类
3):增加程序的健壮性,代码可以被多个线程共享,代码和数据独立
因为一个线程只能启动一次,通过Thread实现线程时,线程和线程所要执行的任务是捆绑在一起的。也就使得一个任务只能启动一个线程,不同的线程执行的任务是不相同=的,所以没有必要,也不能让两个线程共享彼此任务中的资源。
一个任务可以启动多个线程,通过Runnable方式实现的线程,实际是开辟一个线程,将任务传递进去,由此线程执行。可以实例化多个 Thread对象,将同一任务传递进去,也就是一个任务可以启动多个线程来执行它。这些线程执行的是同一个任务,所以他们的资源是共享。
两种不同的线程实现方式本身就决定了其是否能进行资源共享。
4):线程池只能放入实现Runable或callable类线程,不能直接放入继承Thread的类????????
注:main方法其实也是一个线程。在java中所以的线程都是同时启动的,至于什么时候,哪个先执行,完全看谁先得到CPU的资源。
在java中,每次程序运行至少启动2个线程。一个是main线程,一个是垃圾收集线程。因为每当使用java命令执行一个类的时候,实际上都会启动一个JVM,每一个jVM在就是在操作系统中启动了一个进程。
线程池
线程池改进了一个应用程序的响应时间。由于线程池中的线程已经准备好且等待被分配任务,应用程序可以直接拿来使用而不用新建一个线程。
线程池节省了CLR 为每个短生存周期任务创建一个完整的线程的开销并可以在任务完成后回收资源。
线程池根据当前在系统中运行的进程来优化线程时间片。
线程池允许我们开启多个任务而不用为每个线程设置属性。
- 线程池允许我们为正在执行的任务的程序参数传递一个包含状态信息的对象引用。
- 线程池可以用来解决处理一个特定请求最大线程数量限制问题。
本质上来讲,我们使用线程池主要就是为了减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务;节约应用内存(线程开的越多,消耗的内存也就越大,最后死机)
如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间。
ThreadPoolExecutor类是线程池中最核心的一个类
corePoolSize 核心池的大小
maximumPoolSize 线程池允许的最大线程数,他表示最大能创建多少个线程。
keepAliveTime 当线程数超过核心池时,线程没有任务执行时等待多长时间会终止。
unit:参数keepAliveTime的时间单位
workQueue:一个阻塞队列,用来存储等待执行的任务,当线程池中的线程数超过它的corePoolSize的时候,线程会进入阻塞队列进行阻塞等待。通过workQueue,线程池实现了阻塞功能。有三种选择
1
2
3有界任务队列ArrayBlockingQueue; 基于数组的先进先出队列,此队列创建是必须指定大小。
无界任务队列LinkedBlockingQueue; 基于链表的先进先出队列,如果创建时没有指定大侠你,则默认Integer.MAX_VALUE。
直接提交队列SynchronousQueue;它不会保存提交的任务,而是将直接新建一个线程来执行新来的任务threadFactory:线程工厂,主要用来创建线程;
handler:表示当拒绝处理任务时的策略,4种策略。
1
2
3
4ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
线程池实现原理
线程池的5种状态
- RUNNING=-1 执行状态
- SHUTDOWN=0 调用了shutdown()方法,此时线程池不能够接受新的任务,它会等待所有任务执行完毕;
- STOP=1 调用了shutdownNow()方法此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务;
- TIDYING=3
- TERMINATED=3 所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为TERMINATED状态。

1、RUNNING
(1) 状态说明:线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。
(02) 状态切换:线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0!
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
2、 SHUTDOWN
(1) 状态说明:线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。
(2) 状态切换:调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN。
3、STOP
(1) 状态说明:线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
(2) 状态切换:调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP。
4、TIDYING
(1) 状态说明:当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
(2) 状态切换:当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。
当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING。
5、 TERMINATED
(1) 状态说明:线程池彻底终止,就变成TERMINATED状态。
(2) 状态切换:线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED。
线程中的方法
- Thread.yield() 线程让步,比如从运行状态变为就绪状态,然后所有线程一块重新竞争,抢占CPU,包括yield线程在内。
sleep()和wait()差别
- sleep()是属于Thread类中,wait()属于Object类中。
sleep()调用不会释放锁,过了限制时间后自动恢复运行状态。调用wait()方法时,线程会放弃对象锁,进入等待此对象的等待锁定池。只有调动这个对象的notify()方法,才会进入对象锁定池准备 然后等待获得对象锁进入运行状态。
AtomicInteger是在使用非阻塞算法实现并发控制,在一些高并发程序中非常适合,但并不能每一种场景都适合,不同场景要使用使用不同的数值类。Atomic包里的类基本都是使用Unsafe实现的包装类。这是由硬件提供原子操作指令实现的,这里面用到了一种并发技术:CAS。在非激烈竞争的情况下,开销更小,速度更快。
线程状态转换
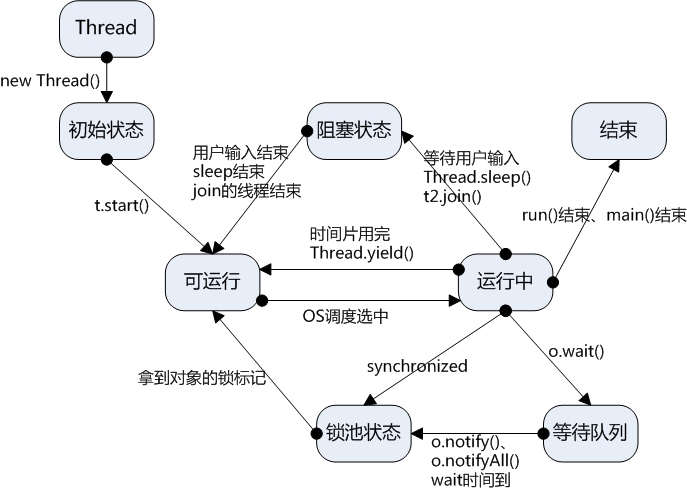
1、新建状态(New):新创建了一个线程对象。
2、就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
3、运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
4、阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
(一)、等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。(wait会释放持有的锁)
(二)、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池中。
(三)、其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。(注意,sleep是不会释放持有的锁)
5、死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
线程调度
线程的调度
1、调整线程优先级:Java线程有优先级,优先级高的线程会获得较多的运行机会。
Java线程的优先级用整数表示,取值范围是1~10,Thread类有以下三个静态常量:
static int MAX_PRIORITY
线程可以具有的最高优先级,取值为10。
static int MIN_PRIORITY
线程可以具有的最低优先级,取值为1。
static int NORM_PRIORITY
分配给线程的默认优先级,取值为5。
Thread类的setPriority()和getPriority()方法分别用来设置和获取线程的优先级。
每个线程都有默认的优先级。主线程的默认优先级为Thread.NORM_PRIORITY。
线程的优先级有继承关系,比如A线程中创建了B线程,那么B将和A具有相同的优先级。
JVM提供了10个线程优先级,但与常见的操作系统都不能很好的映射。如果希望程序能移植到各个操作系统中,应该仅仅使用Thread类有以下三个静态常量作为优先级,这样能保证同样的优先级采用了同样的调度方式。
2、线程睡眠:Thread.sleep(long millis)方法,使线程转到阻塞状态。millis参数设定睡眠的时间,以毫秒为单位。当睡眠结束后,就转为就绪(Runnable)状态。sleep()平台移植性好。
3、线程等待:Object类中的wait()方法,导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 唤醒方法。这个两个唤醒方法也是Object类中的方法,行为等价于调用 wait(0) 一样。
4、线程让步:Thread.yield() 方法,暂停当前正在执行的线程对象,把执行机会让给相同或者更高优先级的线程。
5、线程加入:join()方法,等待其他线程终止。在当前线程中调用另一个线程的join()方法,则当前线程转入阻塞状态,直到另一个进程运行结束,当前线程再由阻塞转为就绪状态。
6、线程唤醒:Object类中的notify()方法,唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个 wait 方法,在对象的监视器上等待。 直到当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程。被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争;例如,唤醒的线程在作为锁定此对象的下一个线程方面没有可靠的特权或劣势。类似的方法还有一个notifyAll(),唤醒在此对象监视器上等待的所有线程。
注意:Thread中suspend()和resume()两个方法在JDK1.5中已经废除,不再介绍。因为有死锁倾向。
常用函数
sleep(long millis): 在指定的毫秒数内让当前正在执行的线程休眠(暂停执行)
join():指等待t线程终止。
为什么要用join()方法
在很多情况下,主线程生成并起动了子线程,如果子线程里要进行大量的耗时的运算,主线程往往将于子线程之前结束,但是如果主线程处理完其他的事务后,需要用到子线程的处理结果,也就是主线程需要等待子线程执行完成之后再结束,这个时候就要用到join()方法了。
yield():暂停当前正在执行的线程对象,并执行其他线程。
Thread.yield()方法作用是:暂停当前正在执行的线程对象,并执行其他线程。
yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。可能调度器立马又调度了该线程运行。
setPriority(): 更改线程的优先级。
MIN_PRIORITY = 1
NORM_PRIORITY = 5
MAX_PRIORITY = 10interrupt():不要以为它是中断某个线程!它只是线线程发送一个中断信号,让线程在无限等待时(如死锁时)能抛出异常,从而结束线程,但是如果你吃掉了这个异常,那么这个线程还是不会中断的!
wait()
Obj.wait(),与Obj.notify()必须要与synchronized(Obj)一起使用,也就是wait,与notify是针对已经获取了Obj锁进行操作,从语法角度来说就是Obj.wait(),Obj.notify必须在synchronized(Obj){…}语句块内,否则会抛出IllegalMonitorStateException。从功能上来说wait就是说线程在获取对象锁后,主动释放对象锁,同时本线程休眠。直到有其它线程调用对象的notify()唤醒该线程,才能继续获取对象锁,并继续执行。相应的notify()就是对对象锁的唤醒操作。但有一点需要注意的是notify()调用后,并不是马上就释放对象锁的,而是在相应的synchronized(){}语句块执行结束,自动释放锁后,JVM会在wait()对象锁的线程中随机选取一线程,赋予其对象锁,唤醒线程,继续执行。这样就提供了在线程间同步、唤醒的操作。Thread.sleep()与Object.wait()二者都可以暂停当前线程,释放CPU控制权,主要的区别在于Object.wait()在释放CPU同时,释放了对象锁的控制
wait为什么需要放在while里边
对于从wait中被notify的进程来说,它在被notify之后还需要重新检查是否符合执行条件,如果不符合,就必须再次被wait,如果符合才能往下执行。所以:wait方法应该使用循环模式来调用。
wait为什么必须放在synchronized里边
我们都知道在调用Object.wait()时必须在synchronized块里面,否则会抛出 IllegalMonitorStateException。但是为什么会有该限制,为什么wait()和notify()同时出现才有意义。
wait()往往需要在condition上面协同使用,如果condition不能满足,那么将一直等待。
所以一般是这样使用:
1 | if(!condition){ step1 |
但是condition是由其他线程设置的,所以为了正确工作必须使用内置锁。
线程退出了wait状态不代表condition是正确的:
你可能回虚假的唤醒(一个线程可以从没有收到通知的等待中唤醒),或者
另外虽然condition设置了,但是第三个线程可能会在等待线程唤醒时再次使条件为false,这样可能一直挂起,而唤醒线程如果不执行的话就会永远挂起。
举个例子:
线程A执行step1,此次条件为false,如果是队列,那就是队列为空。
线程B执行step3,将condition置为true,并执行step4发起唤醒通知。
线程A继续执行step2,这样就可能一直阻塞了。
wait和sleep区别
共同点:
- 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数,并返回。
- wait()和sleep()都可以通过interrupt()方法 打断线程的暂停状态 ,从而使线程立刻抛出InterruptedException。
如果线程A希望立即结束线程B,则可以对线程B对应的Thread实例调用interrupt方法。如果此刻线程B正在wait/sleep /join,则线程B会立刻抛出InterruptedException,在catch() {} 中直接return即可安全地结束线程。
需要注意的是,InterruptedException是线程自己从内部抛出的,并不是interrupt()方法抛出的。对某一线程调用 interrupt()时,如果该线程正在执行普通的代码,那么该线程根本就不会抛出InterruptedException。但是,一旦该线程进入到 wait()/sleep()/join()后,就会立刻抛出InterruptedException 。
不同点:
- Thread类的方法:sleep(),yield()等
Object的方法:wait()和notify()等 - 每个对象都有一个锁来控制同步访问。Synchronized关键字可以和对象的锁交互,来实现线程的同步。
sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。 - wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
- sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常,所以sleep()和wait()方法的最大区别是:
- sleep()睡眠时,保持对象锁,仍然占有该锁;
- wait()睡眠时,释放对象锁。
但是wait()和sleep()都可以通过interrupt()方法打断线程的暂停状态,从而使线程立刻抛出InterruptedException(但不建议使用该方法)。
sleep()方法
sleep()使当前线程进入停滞状态(阻塞当前线程),让出CPU的使用、目的是不让当前线程独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会;
sleep()是Thread类的Static(静态)的方法;因此他不能改变对象的机锁,所以当在一个Synchronized块中调用Sleep()方法是,线程虽然休眠了,但是对象的机锁并木有被释放,其他线程无法访问这个对象(即使睡着也持有对象锁)。
在sleep()休眠时间期满后,该线程不一定会立即执行,这是因为其它线程可能正在运行而且没有被调度为放弃执行,除非此线程具有更高的优先级。
wait()方法
wait()方法是Object类里的方法;当一个线程执行到wait()方法时,它就进入到一个和该对象相关的等待池中,同时失去(释放)了对象的机锁(暂时失去机锁,wait(long timeout)超时时间到后还需要返还对象锁);其他线程可以访问;
wait()使用notify或者notifyAlll或者指定睡眠时间来唤醒当前等待池中的线程。
wiat()必须放在synchronized block中,否则会在program runtime时扔出”java.lang.IllegalMonitorStateException“异常。
sleep()和yield()的区别
sleep()使当前线程进入停滞状态,所以执行sleep()的线程在指定的时间内肯定不会被执行;yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
sleep 方法使当前运行中的线程睡眼一段时间,进入不可运行状态,这段时间的长短是由程序设定的,yield 方法使当前线程让出 CPU 占有权,但让出的时间是不可设定的。实际上,yield()方法对应了如下操作:先检测当前是否有相同优先级的线程处于同可运行状态,如有,则把 CPU 的占有权交给此线程,否则,继续运行原来的线程。所以yield()方法称为“退让”,它把运行机会让给了同等优先级的其他线程
另外,sleep 方法允许较低优先级的线程获得运行机会,但 yield() 方法执行时,当前线程仍处在可运行状态,所以,不可能让出较低优先级的线程些时获得 CPU 占有权。在一个运行系统中,如果较高优先级的线程没有调用 sleep 方法,又没有受到 I\O 阻塞,那么,较低优先级线程只能等待所有较高优先级的线程运行结束,才有机会运行。
常见线程名词解释
主线程:JVM调用程序main()所产生的线程。
当前线程:这个是容易混淆的概念。一般指通过Thread.currentThread()来获取的进程。
后台线程:指为其他线程提供服务的线程,也称为守护线程。JVM的垃圾回收线程就是一个后台线程。用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束
前台线程:是指接受后台线程服务的线程,其实前台后台线程是联系在一起,就像傀儡和幕后操纵者一样的关系。傀儡是前台线程、幕后操纵者是后台线程。由前台线程创建的线程默认也是前台线程。可以通过isDaemon()和setDaemon()方法来判断和设置一个线程是否为后台线程。
线程类的一些常用方法: sleep(): 强迫一个线程睡眠N毫秒。 isAlive(): 判断一个线程是否存活。 join(): 等待线程终止。 activeCount(): 程序中活跃的线程数。 enumerate(): 枚举程序中的线程。 currentThread(): 得到当前线程。 isDaemon(): 一个线程是否为守护线程。 setDaemon(): 设置一个线程为守护线程。(用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束) setName(): 为线程设置一个名称。 wait(): 强迫一个线程等待。 notify(): 通知一个线程继续运行。 setPriority(): 设置一个线程的优先级。
线程同步之synchronized关键字
1、synchronized关键字的作用域有二种:
1)是某个对象实例内,synchronized aMethod(){}可以防止多个线程同时访问这个对象的synchronized方法(如果一个对象有多个synchronized方法,只要一个线程访问了其中的一个synchronized方法,其它线程不能同时访问这个对象中任何一个synchronized方法)。这时,不同的对象实例的synchronized方法是不相干扰的。也就是说,其它线程照样可以同时访问相同类的另一个对象实例中的synchronized方法;
2)是某个类的范围,synchronized static aStaticMethod{}防止多个线程同时访问这个类中的synchronized static 方法。它可以对类的所有对象实例起作用。
2、除了方法前用synchronized关键字,synchronized关键字还可以用于方法中的某个区块中,表示只对这个区块的资源实行互斥访问。用法是: synchronized(this){/区块/},它的作用域是当前对象;
3、synchronized关键字是不能继承的,也就是说,基类的方法synchronized f(){} 在继承类中并不自动是synchronized f(){},而是变成了f(){}。继承类需要你显式的指定它的某个方法为synchronized方法;
注意:
A.无论synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁――而且同步方法很可能还会被其他线程的对象访问。
B.每个对象只有一个锁(lock)与之相关联。
C.实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
线程同步:
1、线程同步的目的是为了保护多个线程反问一个资源时对资源的破坏。
2、线程同步方法是通过锁来实现,每个对象都有切仅有一个锁,这个锁与一个特定的对象关联,线程一旦获取了对象锁,其他访问该对象的线程就无法再访问该对象的其他非同步方法。
3、对于静态同步方法,锁是针对这个类的,锁对象是该类的Class对象。静态和非静态方法的锁互不干预。一个线程获得锁,当在一个同步方法中访问另外对象上的同步方法时,会获取这两个对象锁。
4、对于同步,要时刻清醒在哪个对象上同步,这是关键。
5、编写线程安全的类,需要时刻注意对多个线程竞争访问资源的逻辑和安全做出正确的判断,对“原子”操作做出分析,并保证原子操作期间别的线程无法访问竞争资源。
6、当多个线程等待一个对象锁时,没有获取到锁的线程将发生阻塞。
7、死锁是线程间相互等待锁锁造成的,在实际中发生的概率非常的小。真让你写个死锁程序,不一定好使,呵呵。但是,一旦程序发生死锁,程序将死掉。
线程数据传递
1、通过构造方法传递数据
在创建线程时,必须要建立一个Thread类的或其子类的实例。因此,我们不难想到在调用start方法之前通过线程类的构造方法将数据传入线程。并将传入的数据使用类变量保存起来,以便线程使用(其实就是在run方法中使用)。
1 | package mythread; |
由于这种方法是在创建线程对象的同时传递数据的,因此,在线程运行之前这些数据就就已经到位了,这样就不会造成数据在线程运行后才传入的现象。如果要传递更复杂的数据,可以使用集合、类等数据结构。使用构造方法来传递数据虽然比较安全,但如果要传递的数据比较多时,就会造成很多不便。由于Java没有默认参数,要想实现类似默认参数的效果,就得使用重载,这样不但使构造方法本身过于复杂,又会使构造方法在数量上大增。因此,要想避免这种情况,就得通过类方法或类变量来传递数据。
2.通过变量和方法传递数据
向对象中传入数据一般有两次机会,第一次机会是在建立对象时通过构造方法将数据传入,另外一次机会就是在类中定义一系列的public的方法或变量(也可称之为字段)。然后在建立完对象后,通过对象实例逐个赋值。下面的代码是对MyThread1类的改版,使用了一个setName方法来设置 name变量:
1 | package mythread; |
3. 通过回调函数传递数据
上面讨论的两种向线程中传递数据的方法是最常用的。但这两种方法都是main方法中主动将数据传入线程类的。这对于线程来说,是被动接收这些数据的。然而,在有些应用中需要在线程运行的过程中动态地获取数据,如在下面代码的run方法中产生了3个随机数,然后通过Work类的process方法求这三个随机数的和,并通过Data类的value将结果返回。从这个例子可以看出,在返回value之前,必须要得到三个随机数。也就是说,这个 value是无法事先就传入线程类的。
1 | package mythread; |
IO密集型和CPU密集型比较
- IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,意思就是CPU在等硬盘和内存
- CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,意思就是硬盘和内存在等CPU
volatile无法保证线程安全
只能在有限的一些情形下使用 volatile 变量替代锁。要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件:
- 对变量的写操作不依赖于当前值。
- 该变量没有包含在具有其他变量的不变式中。
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
第一个条件的限制使 volatile 变量不能用作线程安全计数器。虽然增量操作(x++)看上去类似一个单独操作,实际上它是一个由读取-修改-写入操作序列组成的组合操作,必须以原子方式执行,而 volatile 不能提供必须的原子特性。实现正确的操作需要使 x 的值在操作期间保持不变,而 volatile 变量无法实现这点。(然而,如果将值调整为只从单个线程写入,那么可以忽略第一个条件。)
大多数编程情形都会与这两个条件的其中之一冲突,使得 volatile 变量不能像 synchronized 那样普遍适用于实现线程安全。
JAVA之I/O:
什么是I/O
I/O 即输入Input/ 输出Output的缩写,最容易让人联想到的就是屏幕这样的输出设备以及键盘鼠标这一类的输入设备,其广义上的定义就是:数据在内部存储器和外部存储器或其他周边设备之间的输入和输出;我们可以从定义上看到问题的核心就是:数据/ 输入/ 输出,在Java中,主要就是涉及到磁盘 I/O 和网络 I/O 两种了;
简单理解Java 流(Stream)通常我们说 I/O 都会涉及到诸如输入流、输出流这样的概念,那么什么是流呢?流是一个抽象但形象的概念,你可以简单理解成一个数据的序列,输入流表示从一个源读取数据,输出流则表示向一个目标写数据,在Java程序中,对于数据的输入和输出都是采用 “流” 这样的方式进行的,其设备可以是文件、网络、内存等;流具有方向性,至于是输入流还是输出流则是一个相对的概念,一般以程序为参考,如果数据的流向是程序至设备,我们成为输出流,反之我们称为输入流。
Java中的 I/O 类库的基本架构
在 I/O 库上也一直在做持续的优化,例如JDK1.4引入的 NIO,JDK1.7引入的 NIO 2.0,都一定程度上的提升了 I/O 的性能;
Java的 I/O 操作类在包 java.io下,有将近80个类,这些类大概可以分成如下 4 组:
- 基于字节操作的 I/O 接口:InputStream 和 OutputStream;
- 基于字符操作的 I/O 接口:Writer 和 Reader;
- 基于磁盘操作的 I/O 接口:File;
- 基于网络操作的 I/O 接口:Socket;
前两组主要是传输数据的数据格式,后两组主要是传输数据的方式,虽然Socket类并不在java.io包下,但这里仍然把它们划分在了一起;I/O 只是人机交互的一种手段,除了它们能够完成这个交互功能外,我们更多的应该是关注如何提高它的运行效率;00.基于字节的 I/O 操作接口基于字节的 I/O 操作的接口输入和输出分别对应是 InputStream 和 OutputStream,InputStream 的类层次结构如下图:
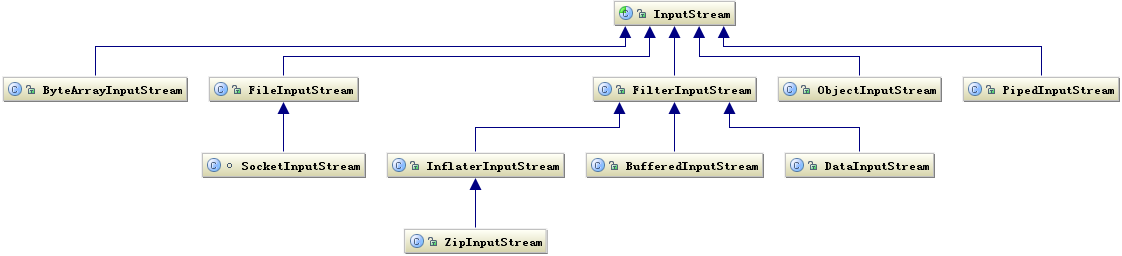
输入流根据数据类型和操作方式又被划分成若干个子类,每个子类分别处理不同操作类型,OutputStream 输出流的类层次结构也是类似,如下图所示:

1)操作数据的方式是可以组合使用的(也就是装饰器模式):例如:
OutputStream out = new BufferedOutputStream(new ObjectOutputStream(new FileOutputStream(“fileName”));
2)必须要指定流最终写到什么地方:要么是写到磁盘,要么是写到网络中,但重点是你必须说明这一点,而且你会发现其实SocketOutputStream是属于FileOutputStream下的,也就是说写网络实际上也是写文件,只不过写网络还有一步需要处理,就是让底层的操作系统知道我这个数据是需要传送到其他地方而不是本地磁盘上的;
01.基于字符的 I/O 操作接口不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,所以 I/O 操作的都是字节而不是字符,但是在我们日常的程序中操作的数据几乎都是字符,所以为了操作方便当然要提供一个可以直接写字符的 I/O 接口。而且从字符到字节必须经过编码转换,而这个编码又非常耗时,还经常出现乱码的问题,所以 I/O 的编码问题经常是让人头疼的问题。
读字符的操作接口中是 int read(char cbuf[], int off, int len),写字符也类似,返回读到的 n 个字节数,不管是 Writer 还是 Reader 类它们都只定义了读取或写入的数据字符的方式,也就是怎么写或读,但是并没有规定数据要写到哪去,写到哪去就是我们后面要讨论的基于磁盘和网络的工作机制。
01.字节与字符的转化接口另外数据持久化或网络传输都是以字节进行的,所以必须要有字符到字节或字节到字符的转化。字符到字节需要转化,其中读的转化过程如下图所示:
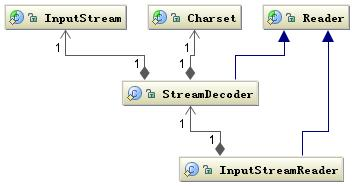
InputStreamReader 类是字节到字符的转化桥梁,InputStream 到 Reader 的过程要指定编码字符集,否则将采用操作系统默认字符集,很可能会出现乱码问题。StreamDecoder 正是完成字节到字符的解码的实现类。
磁盘 I/O 的工作机制
几种访问文件的方式我们知道,读取和写入文件 I/O 操作都调用的是操作系统提供给我们的接口,因为磁盘设备是归操作系统管的,而只要是系统调用都可能存在内核空间地址和用户空间地址切换的问题,这是为了保证用户进程不能直接操作内核,保证内核的安全而设计的,现代的操作系统将虚拟空间划分成了内核空间和用户空间两部分并实现了隔离,但是这样虽然保证了内核程序运行的安全性,但是也必然存在数据可能需要从内核空间向用户用户空间复制的问题;
如果遇到非常耗时的操作,如磁盘 I/O,数据从磁盘复制到内核空间,然后又从内核空间复制到用户空间,将会非常耗时,这时操作系统为了加速 I/O 访问,在内核空间使用缓存机制,也就是将从磁盘读取的文件按照一定的组织方式进行缓存,入股用户程序访问的是同一段磁盘地址的空间数据,那么操作系统将从内核缓存中直接取出返回给用户程序,这样就可以减少 I/O 的响应时间;
访问文件的方式:
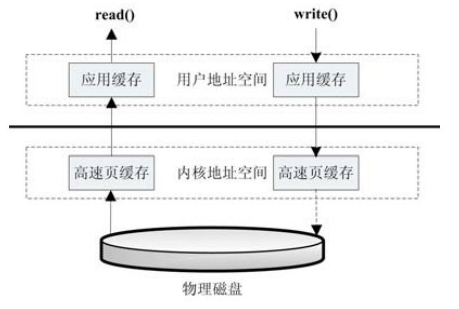
读取的方式是,当应用程序调用read()接口时:
- ①操作系统首先检查在内核的高速缓存中是否存在需要的数据,如果有,那么直接从缓存中返回;
- ②如果没有,则从磁盘中读取,然后缓存在操作系统的缓存中;
01.直接 I/O 方式
所谓的直接 I/O 的方式就是应用程序直接访问磁盘数据,而不经过操作系统内核数据缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制;这种访问文件的方式通常是在对数据的缓存管理由应用程序实现的数据库管理系统中,如在数据库管理系统中,系统明确地知道应该缓存哪些数据,应该失效哪些数据,还可以对一些热点数据做预加载,提前将热点数据加载到内存,可以加速数据的访问效率,而这些情况如果是交给操作系统进行缓存,那么操作系统将不知道哪些数据是热点数据,哪些是只会访问一次的数据,因为它只是简单的缓存最近一次从磁盘读取的数据而已;
但是直接 I/O 也有负面影响,如果访问的数据不再应用程序缓存之中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢,因此直接 I/O 通常与 异步 I/O 进行结合以达到更好的性能;
Java 序列化技术
Java序列化就是将一个对象转化成一串二进制表示的字节数组,通过保存或转移这些字节数据来达到持久化的目的。需要持久化,对象必须继承 java.io.Serializable 接口,或者将其转为字节数组,用于网络传输;注意:一个类的对象想要序列化成功,必须满足两个条件
- ①实现上述的接口;
- ②保证该类的所有属性必须都是可序列化的,如果不希望某个属性序列化(例如一些敏感信息),可以加上transient关键字;
或许会有留意到诸如这样的代码:
private static final long serialVersionUID = 876323262645176354L;
就这一长串的东西也不知道是在干嘛的,但这其实是为了保证序列化版本的兼容性,即在版本升级后序列化仍保持对象的唯一性;我们通过上述的修改也感受到了其中的一二,但是问题是:我们并没有在需要序列化的对象中写任何关于这个UID的代码呀?这是个有趣的问题,通常情况下,如果我们实现了序列化接口,但是没有自己显式的声明这个UID的话,那么JVM就会根据该类的类名、属性名、方法名等自己计算出一个独一无二的变量值,然后将这个变量值一同序列化到文件之中,而在反序列化的时候同样,会根据该类计算出一个独一无二的变量然后进行比较,不一致就会报错,但是我怀着强烈的好奇心去反编译了一下.class文件,并没有发现编译器写了UDI这一类的东西,我看《深入分析 Java Web 技术内幕》中说,实际上是写到了二进制文件里面了;
- 不显式声明的缺点:一旦写好了某一个类,那么想要修改就不行了,所以我们最好自己显式的去声明;
- 显式声明的方式:①使用默认的1L作用UID;②根据类名、接口名等生成一个64位的哈希字段,现在的编译器如IDEA、Eclipse都有这样的功能
序列化用来干什么?虽然我们上面的程序成功将一个对象序列化保存到磁盘,然后从磁盘还原,但是这样的功能到底可以应用在哪些场景?到底可以干一些什么样的事情呢?下面举一些在实际应用中的例子:
- Web服务器中保存Session对象,如Tomcat会在服务器关闭时把session序列化存储到一个名为session.ser的文件之中,这个过程称为session的钝化;
- 网络上传输对象,如分布式应用等;
关于序列化的一些细节
1.如果一个类没有实现Serializable接口,但是它的基类实现了,那么这个类也是可以序列化的;
2.相反,如果一个类实现了Serializable接口,但是它的父类没有实现,那么这个类还是可以序列化(Object是所有类的父类),但是序列化该子类对象,然后反序列化后输出父类定义的某变量的数值,会发现该变量数值与序列化时的数值不同(一般为null或者其他默认值),而且这个父类里面必须有无参的构造方法,不然子类反序列化的时候会报错。
网络 I/O 工作机制
数据从一台主机发送到网络中的另一台主机需要经过很多步骤,首先双方需要有沟通的意向,然后要有能够沟通的物理渠道(物理链路),其次,还要保障双方能够正常的进行交流,例如语言一致的问题、说话顺序的问题等等等;
Java Socket 的工作机制看到有地方说:网络 I/O 的实质其实就是对 Socket 的读取;那Socket 这个概念没有对应到一个具体的实体,它是描述计算机之间完成相互通信一种抽象功能。打个比方,可以把 Socket 比作为两个城市之间的交通工具,有了它,就可以在城市之间来回穿梭了。交通工具有多种,每种交通工具也有相应的交通规则。Socket 也一样,也有多种。大部分情况下我们使用的都是基于 TCP/IP 的流套接字,它是一种稳定的通信协议。
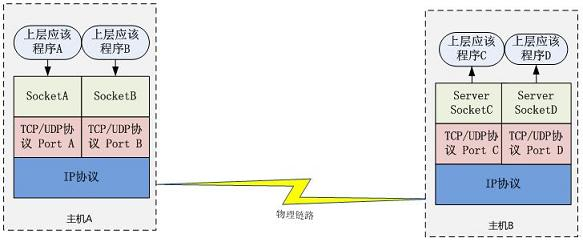
主机 A 的应用程序要能和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层 TCP/IP 协议来建立 TCP 连接。建立 TCP 连接需要底层 IP 协议来寻址网络中的主机。我们知道网络层使用的 IP 协议可以帮助我们根据 IP 地址来找到目标主机,但是一台主机上可能运行着多个应用程序,如何才能与指定的应用程序通信就要通过 TCP 或 UPD 的地址也就是端口号来指定。这样就可以通过一个 Socket 实例唯一代表一个主机上的一个应用程序的通信链路了。
建立通信链路当客户端要与服务端通信,客户端首先要创建一个 Socket 实例,操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,并创建一个包含本地和远程地址和端口号的套接字数据结构,这个数据结构将一直保存在系统中直到这个连接关闭。在创建 Socket 实例的构造函数正确返回之前,将要进行 TCP 的三次握手协议,TCP 握手协议完成后,Socket 实例对象将创建完成,否则将抛出 IOException 错误。
与之对应的服务端将创建一个 ServerSocket 实例,ServerSocket 创建比较简单只要指定的端口号没有被占用,一般实例创建都会成功,同时操作系统也会为 ServerSocket 实例创建一个底层数据结构,这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下都是“*”即监听所有地址。之后当调用 accept() 方法时,将进入阻塞状态,等待客户端的请求。当一个新的请求到来时,将为这个连接创建一个新的套接字数据结构,该套接字数据的信息包含的地址和端口信息正是请求源地址和端口。这个新创建的数据结构将会关联到 ServerSocket 实例的一个未完成的连接数据结构列表中,注意这时服务端与之对应的 Socket 实例并没有完成创建,而要等到与客户端的三次握手完成后,这个服务端的 Socket 实例才会返回,并将这个 Socket 实例对应的数据结构从未完成列表中移到已完成列表中。所以 ServerSocket 所关联的列表中每个数据结构,都代表与一个客户端的建立的 TCP 连接。
数据传输传输数据是我们建立连接的主要目的,如何通过 Socket 传输数据,下面将详细介绍。
当连接已经建立成功,服务端和客户端都会拥有一个 Socket 实例,每个 Socket 实例都有一个 InputStream 和 OutputStream,正是通过这两个对象来交换数据。同时我们也知道网络 I/O 都是以字节流传输的。当 Socket 对象创建时,操作系统将会为 InputStream 和 OutputStream 分别分配一定大小的缓冲区,数据的写入和读取都是通过这个缓存区完成的。写入端将数据写到 OutputStream 对应的 SendQ 队列中,当队列填满时,数据将被发送到另一端 InputStream 的 RecvQ 队列中,如果这时 RecvQ 已经满了,那么 OutputStream 的 write 方法将会阻塞直到 RecvQ 队列有足够的空间容纳 SendQ 发送的数据。值得特别注意的是,这个缓存区的大小以及写入端的速度和读取端的速度非常影响这个连接的数据传输效率,由于可能会发生阻塞,所以网络 I/O 与磁盘 I/O 在数据的写入和读取还要有一个协调的过程,如果两边同时传送数据时可能会产生死锁,在后面 NIO 部分将介绍避免这种情况。
NIO
NIO 的工作方式,BIO 带来的挑战,BIO 即阻塞 I/O,不管是磁盘 I/O 还是网络 I/O,数据在写入 OutputStream 或者从 InputStream 读取时都有可能会阻塞。一旦有线程阻塞将会失去 CPU 的使用权,这在当前的大规模访问量和有性能要求情况下是不能接受的。虽然当前的网络 I/O 有一些解决办法,如一个客户端一个处理线程,出现阻塞时只是一个线程阻塞而不会影响其它线程工作,还有为了减少系统线程的开销,采用线程池的办法来减少线程创建和回收的成本,但是有一些使用场景仍然是无法解决的。如当前一些需要大量 HTTP 长连接的情况,像淘宝现在使用的 Web 旺旺项目,服务端需要同时保持几百万的 HTTP 连接,但是并不是每时每刻这些连接都在传输数据,这种情况下不可能同时创建这么多线程来保持连接。即使线程的数量不是问题,仍然有一些问题还是无法避免的。如这种情况,我们想给某些客户端更高的服务优先级,很难通过设计线程的优先级来完成,另外一种情况是,我们需要让每个客户端的请求在服务端可能需要访问一些竞争资源,由于这些客户端是在不同线程中,因此需要同步,而往往要实现这些同步操作要远远比用单线程复杂很多。以上这些情况都说明,我们需要另外一种新的 I/O 操作方式。
NIO 的工作机制很多人都把NIO翻译成New IO,但我更觉得No-Block IO更接近它的本意,也就是非阻塞式IO,它虽然是非阻塞式的,但它是同步的,我们先看一下 NIO 涉及到的关联类图,如下:
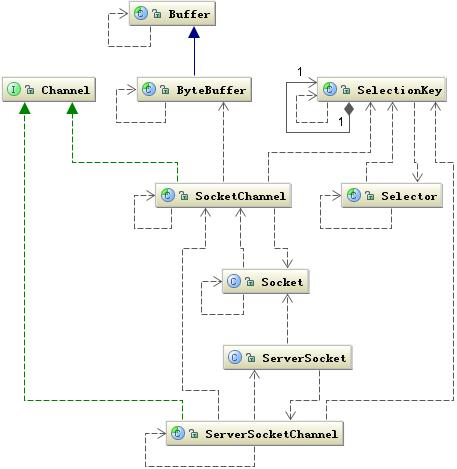
上图中有两个关键类:Channel 和 Selector,它们是 NIO 中两个核心概念。我们还用前面的城市交通工具来继续比喻 NIO 的工作方式,这里的 Channel 要比 Socket 更加具体,它可以比作为某种具体的交通工具,如汽车或是高铁等,而 Selector 可以比作为一个车站的车辆运行调度系统,它将负责监控每辆车的当前运行状态:是已经出战还是在路上等等,也就是它可以轮询每个 Channel 的状态。这里还有一个 Buffer 类,它也比 Stream 更加具体化,我们可以将它比作为车上的座位,Channel 是汽车的话就是汽车上的座位,高铁上就是高铁上的座位,它始终是一个具体的概念,与 Stream 不同。Stream 只能代表是一个座位,至于是什么座位由你自己去想象,也就是你在去上车之前并不知道,这个车上是否还有没有座位了,也不知道上的是什么车,因为你并不能选择,这些信息都已经被封装在了运输工具(Socket)里面了,对你是透明的。
NIO 引入了 Channel、Buffer 和 Selector 就是想把这些信息具体化,让程序员有机会控制它们,如:当我们调用 write() 往 SendQ 写数据时,当一次写的数据超过 SendQ 长度是需要按照 SendQ 的长度进行分割,这个过程中需要有将用户空间数据和内核地址空间进行切换,而这个切换不是你可以控制的。而在 Buffer 中我们可以控制 Buffer 的 capacity,并且是否扩容以及如何扩容都可以控制。
1 | public void selector() throws IOException { |
调用 Selector 的静态工厂创建一个选择器,创建一个服务端的 Channel 绑定到一个 Socket 对象,并把这个通信信道注册到选择器上,把这个通信信道设置为非阻塞模式。然后就可以调用 Selector 的 selectedKeys 方法来检查已经注册在这个选择器上的所有通信信道是否有需要的事件发生,如果有某个事件发生时,将会返回所有的 SelectionKey,通过这个对象 Channel 方法就可以取得这个通信信道对象从而可以读取通信的数据,而这里读取的数据是 Buffer,这个 Buffer 是我们可以控制的缓冲器。
在上面的这段程序中,是将 Server 端的监听连接请求的事件和处理请求的事件放在一个线程中,但是在实际应用中,我们通常会把它们放在两个线程中,一个线程专门负责监听客户端的连接请求,而且是阻塞方式执行的;另外一个线程专门来处理请求,这个专门处理请求的线程才会真正采用 NIO 的方式,像 Web 服务器 Tomcat 和 Jetty 都是这个处理方式。
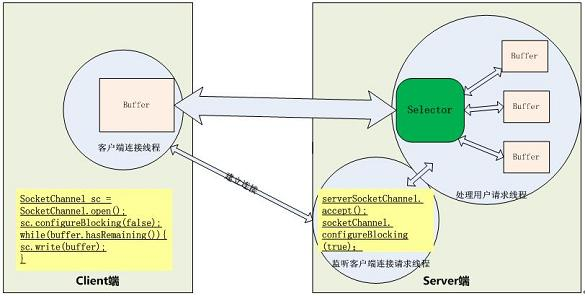
上图中的 Selector 可以同时监听一组通信信道(Channel)上的 I/O 状态,前提是这个 Selector 要已经注册到这些通信信道中。选择器 Selector 可以调用 select() 方法检查已经注册的通信信道上的是否有 I/O 已经准备好,如果没有至少一个信道 I/O 状态有变化,那么 select 方法会阻塞等待或在超时时间后会返回 0。上图中如果有多个信道有数据,那么将会将这些数据分配到对应的数据 Buffer 中。所以关键的地方是有一个线程来处理所有连接的数据交互,每个连接的数据交互都不是阻塞方式,所以可以同时处理大量的连接请求。
Java NIO 实例上面从 NIO 中引入了一些概念,下面我们对这些概念再来进行简单的复述和补充:
- 缓冲区Buffer:缓冲区是一个对象,里面存的是数据,NIO进行通讯,传递的数据,都包装到Buffer中,Buffer是一个抽象类。子类有ByteBuffer、CharBuffer等,常用的是字节缓冲区,也就是ByteBuffer;
- 通道Channel:channel是一个通道,通道就是通流某种物质的管道,在这里就是通流数据,他和流的不同之处就在于,流是单向的,只能向一个方向流动,而通道是一个管道,有两端,是双向的,可以进行读操作,也可以写操作,或者两者同时进行;
- 多路复用器Selector:多路复用器是一个大管家,他管理着通道,通道把自己注册到Selector上面,Selector会轮询注册到自己的管道,通过判断这个管道的不同的状态,来进行相应的操作;
NIO 工作机制的核心思想就是:客户端和服务器端都是使用的通道,通道具有事件,可以将事件注册到多路复选器上,事件有就绪和非就绪两种状态,就绪的状态会放到多路复选器的就绪键的集合中,起一个线程不断地去轮询就绪的状态,根据不同的状态做不同的处理/
NIO 和 IO 的主要区别面向流与面向缓冲.
Java NIO和IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。
阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
选择器(Selectors)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
JDK和JRE有什么区别:
1.JDK
JDK是Java Development Kit的缩写,是Java的开发工具包,主要包含了各种类库和工具,当然也包含了另外一个JRE.。那么为什么要包含另外一个JRE呢?而且<JDK安装目录>/JRE/bin目录下,包含有server一个文件夹~包含一个jvm.dll,这说明JDK提供了一个虚拟机。
另外,JDK的bin目录下有各种Java程序需要用到的命令,与JRE的bin目录最明显的区别就是JDK文件下才有javac,这一点很好理解,因为JRE只是一个运行环境而已,与开发无关。正因为如此,具备开发功能的JDK所包含的JRE下才会同时有server的JVM,而仅仅作为运行环境的JRE下,只需要server的jvm.dll就够了。
注意:JDK所提供的运行环境和工具度需要进行环境变量的配置以后,才能使用,最主要的配置就是把<JDK安装目录>/bin目录设置为Path环境变量值的一部分。
2.JRE
JRE是Java Runtime Environment的缩写,是Java程序的运行环境。既然是运行,当然要包含JVM,也就是所谓的Java虚拟机,还有所以的Java类库的class文件,都在lib目录下,并且都打包成了jar。
Exception和Error的区别, 运行时异常和一般异常的区别
Exception和Error都继承了-Throwable类,在Java中只有Throwable类型的实例才可以被抛出或者捕获,是异常处理机制的基本组成类型。
Exception和Error体现了Java平台设计者对不同异常情况的分类。Exception是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Error是指正常情况下,不大可能出现的情况,绝大部分的Error都会导致程序(比如JVM自身)处于非正常的,不可恢复状态。比如OutOfMemoryError之类,都是Error的子类。
Exception分为可检查异常和不检查异常,可检查异常在源代码里必须显式的进行捕获处理,这是编译器检查的一部分。
Error属于Throwable,而不是Exception。
RuntimeException:RuntimeException继承了Exception,而不是直接继Error,这个表示系统异常,比较严重。
不受检查异常的基类RuntimeException,在方法的声明中没有声明,但在方法的运行过程中发生的各种异常被称为”不被检查的异常”。这种异常是错误,会被自动捕获。
String,StringBuffer, StringBuilder的区别是什么?String为什么是不可变的?
1、String是字符串常量,StringBuffer和StringBuilder都是字符串变量。后两者的字符内容可变,而前者创建后内容不可变。
2、String不可变是因为在JDK中String类被声明为一个final类。
3、StringBuffer是线程安全的,而StringBuilder是非线程安全的。
ps:线程安全会带来额外的系统开销,所以StringBuilder的效率比StringBuffer高。如果对系统中的线程是否安全很掌握,可用StringBuffer,在线程不安全处加上关键字Synchronize。
非静态的拼接逻辑在 JDK 8 中会自动被 javac 转换为 StringBuilder 操作;而在 JDK 9 里面,则是体现了思路的变化。Java 9 利用 InvokeDynamic,将字符串拼接的优化与 javac 生成的字节码解耦,假设未来 JVM 增强相关运行时实现,将不需要依赖 javac 的任何修改。
string为什么会被设计为不可变:https://blog.csdn.net/renfufei/article/details/16808775
把常见应用进行堆转储(Dump Heap),然后分析对象组成,会发现平均 25% 的对象是字符串,并且其中约半数是重复的。如果能避免创建重复字符串,可以有效降低内存消耗和对象创建开销。
String 在 Java 6 以后提供了 intern() 方法(显式的排重机制),目的是提示 JVM 把相应字符串缓存起来,以备重复使用。在我们创建字符串对象并调用 intern() 方法的时候,如果已经有缓存的字符串,就会返回缓存里的实例,否则将其缓存起来。一般来说,JVM 会将所有的类似“abc”这样的文本字符串,或者字符串常量之类缓存起来。
JAVA6中,被缓存的字符串存在于永久代中,容易导致OOM
后续版本,主要放在堆中,避免永久代占满的问题,甚至永久代在 JDK 8 中被 MetaSpace(元数据区)替代了。而且,默认缓存大小也在不断地扩大中,从最初的 1009,到 7u40 以后被修改为 60013。
Intrinsic 机制
是一种利用 native 方式 hard-coded 的逻辑,算是一种特别的内联,很多优化还是需要直接使用特定的 CPU 指令。
Intrinsic方法简单的说就是jvm对某些声明为了intrinsic的方法进行特殊的处理,不按照java里提供的代码逻辑或者jni里的实现,而是按照特定平台优化后的指令来处理。
这个机制不仅仅作用于 String。
JAVA9中,引入了Compact Strings的设计,字符串由char数组,改变为一个byte数组加上一个标识编码的所谓的coder.
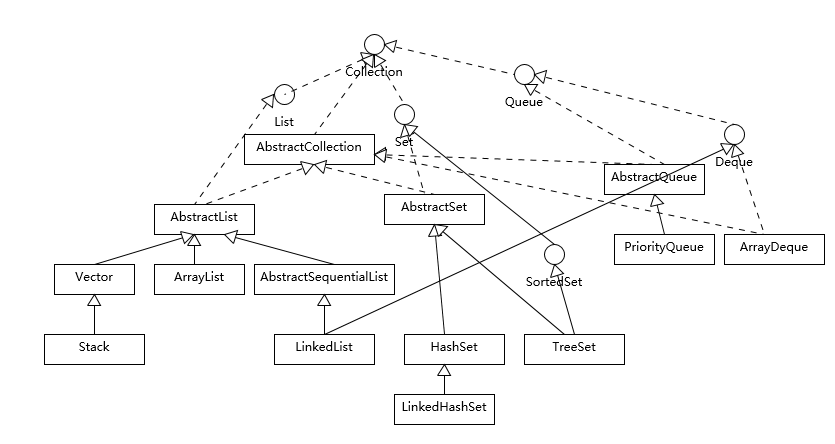
Vector,ArrayList, LinkedList的区别是什么?
1、Vector、ArrayList都是以类似数组的形式存储在内存中,LinkedList则以链表的形式进行存储。
2、List中的元素有序、允许有重复的元素,Set中的元素无序、不允许有重复元素。
3、Vector线程同步,ArrayList、LinkedList线程不同步。
4、LinkedList适合指定位置插入、删除操作,不适合查找;ArrayList、Vector适合查找,不适合指定位置的插入、删除操作。
5、ArrayList在元素填满容器时会自动扩充容器大小的50%,而Vector则是100%,因此ArrayList更节省空间。
- TreeSet 支持自然顺序访问,但是添加、删除、包含等操作要相对低效(log(n) 时间)。
- HashSet 则是利用哈希算法,理想情况下,如果哈希散列正常,可以提供常数时间的添加、删除、包含等操作,但是它不保证有序。
- LinkedHashSet,内部构建了一个记录插入顺序的双向链表,因此提供了按照插入顺序遍历的能力,与此同时,也保证了常数时间的添加、删除、包含等操作,这些操作性能略低于 HashSet,因为需要维护链表的开销。
这些集合类,均不是线程安全的,java.util.concurrent里面的则是线程安全容器。但是这些集合类提供了synchronized方法:
synchronizedList,可以基本实现线程安全。
理解 Java 提供的默认排序算法,具体是什么排序方式以及设计思路等。
需要区分是 Arrays.sort() 还是 Collections.sort() (底层是调用 Arrays.sort());什么数据类型;多大的数据集(太小的数据集,复杂排序是没必要的,Java 会直接进行二分插入排序)等。
- 对于原始数据类型,目前使用的是所谓双轴快速排序(Dual-Pivot QuickSort),是一种改进的快速排序算法,早期版本是相对传统的快速排序。
- 而对于对象数据类型,目前则是使用TimSort.,思想上也是一种归并和二分插入排序(binarySort)结合的优化排序算法。TimSort 并不是 Java 的独创,简单说它的思路是查找数据集中已经排好序的分区(这里叫 run),然后合并这些分区来达到排序的目的。
另外,Java 8 引入了并行排序算法(直接使用 parallelSort 方法),这是为了充分利用现代多核处理器的计算能力,底层实现基于 fork-join 框架(专栏后面会对 fork-join 进行相对详细的介绍),当处理的数据集比较小的时候,差距不明显,甚至还表现差一点;但是,当数据集增长到数万或百万以上时,提高就非常大了,具体还是取决于处理器和系统环境。
在 Java 9 中,Java 标准类库提供了一系列的静态工厂方法,比如,List.of()、Set.of(),大大简化了构建小的容器实例的代码量。根据业界实践经验,我们发现相当一部分集合实例都是容量非常有限的,而且在生命周期中并不会进行修改。
HashTable, HashMap,TreeMap区别?
1、HashTable线程同步,HashMap非线程同步,它是绝大部分利用键值对存取场景的首选。TreeMap 则是基于红黑树的一种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
2、HashTable不允许<键,值>有空值,HashMap允许<键,值>有空值。
3、HashTable使用Enumeration,HashMap使用Iterator。
4、HashTable中hash数组的默认大小是11,增加方式的old*2+1,HashMap中hash数组的默认大小是16,增长方式一定是2的指数倍。
5、TreeMap能够把它保存的记录根据键排序,默认是按升序排序。
http://www.zlmind.com/?spm=a2c4e.11153940.blogcont6656.4.3b4f791dTyQ4Sp&p=679
note: String f5a5a608 的 hashCode 为 0
HashMap 在并发环境可能出现无限循环占用CPU,size不准确等问题。
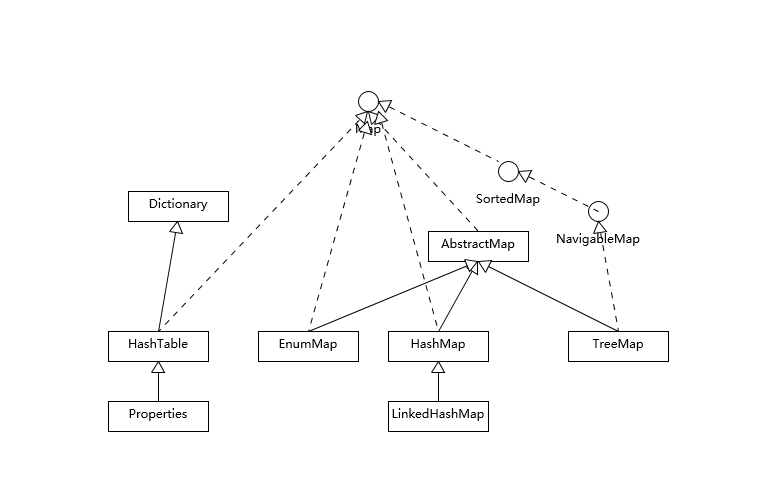
首先,我们先对 Map 相关类型有个整体了解,Map 虽然通常被包括在 Java 集合框架里,但是其本身并不是狭义上的集合类型(Collection),具体你可以参考下面这个简单类图。
大部分使用 Map 的场景,通常就是放入、访问或者删除,而对顺序没有特别要求,HashMap 在这种情况下基本是最好的选择。HashMap 的性能表现非常依赖于哈希码的有效性.
hashCode 和 equals 的一些基本约定:
- equals 相等,hashCode 一定要相等。
- 重写了 hashCode 也要重写 equals。
- hashCode 需要保持一致性,状态改变返回的哈希值仍然要一致。
- equals 的对称、自反、传递等特性。
虽然 LinkedHashMap 和 TreeMap 都可以保证某种顺序,但二者还是非常不同的。
LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
LinkedHashMap的基本实现思想就是—-多态。可以说,理解多态,再去理解LinkedHashMap原理会事半功倍;反之也是,对于LinkedHashMap原理的学习,也可以促进和加深对于多态的理解。
- LinkedHashMap 通常提供的是遍历顺序符合插入顺序,它的实现是通过为条目(键值对)维护一个双向链表。注意,通过特定构造函数,我们可以创建反映访问顺序的实例,所谓的 put、get、compute 等,都算作“访问”。
- 对于 TreeMap,它的整体顺序是由键的顺序关系决定的,通过 Comparator 或 Comparable(自然顺序)来决定。
HashMap 内部实现基本点分析。
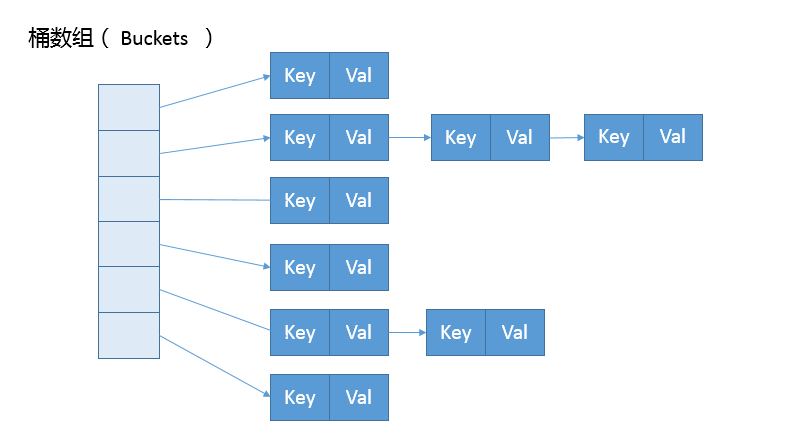
它可以看作是数组(Node<K,V>[] table)和链表结合组成的复合结构,数组被分为一个个桶(bucket),通过哈希值决定了键值对在这个数组的寻址;哈希值相同的键值对,则以链表形式存储,你可以参考下面的示意图。这里需要注意的是,如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),图中的链表就会被改造为树形结构。
ConcurrenthashMap 如何计算size
在 JDK1.7 中,第一种方案他会使用不加锁的模式去尝试多次计算 ConcurrentHashMap 的 size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的。 第二种方案是如果第一种方案不符合,他就会给每个 Segment 加上锁,然后计算 ConcurrentHashMap 的 size 返回。
JDK1.8 实现相比 JDK 1.7 简单很多,只有一种方案,我们直接看 size() 代码:
1 |
|
最大值是 Integer 类型的最大值,但是 Map 的 size 可能超过 MAX_VALUE, 所以还有一个方法 mappingCount(),JDK 的建议使用 mappingCount() 而不是size()。mappingCount() 的代码如下:
1 |
|
以上可以看出,无论是 size() 还是 mappingCount(), 计算大小的核心方法都是 sumCount()。sumCount() 的代码如下:
1 | final long sumCount() { |
分析一下 sumCount() 代码。ConcurrentHashMap 提供了 baseCount、counterCells 两个辅助变量和一个 CounterCell 辅助内部类。sumCount() 就是迭代 counterCells 来统计 sum 的过程。 put 操作时,肯定会影响 size(),在 put() 方法最后会调用 addCount() 方法。
addCount() 代码如下:
如果 counterCells == null, 则对 baseCount 做 CAS 自增操作。
从非拷贝构造函数的实现来看,这个表格(数组)似乎并没有在最初就初始化好,仅仅设置了一些初始值而已。
put方法:
如果表格是 null,resize 方法会负责初始化它,这从 tab = resize() 可以看出。
resize 方法兼顾两个职责,创建初始存储表格,或者在容量不满足需求的时候,进行扩容(resize)。
在放置新的键值对的过程中,如果发生下面条件,就会发生扩容。
1
2if (++size > threshold)
resize();具体键值对在哈希表中的位置(数组 index)取决于下面的位运算:
i = (n - 1) & hash
仔细观察哈希值的源头,我们会发现,它并不是 key 本身的 hashCode,而是来自于 HashMap 内部的另外一个 hash 方法。注意,为什么这里需要将高位数据移位到低位进行异或运算呢?这是因为有些数据计算出的哈希值差异主要在高位,而 HashMap 里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希碰撞。
1 | static final int hash(Object key) { |
resize的问题:
依据 resize 源码,不考虑极端情况(容量理论最大极限由 MAXIMUM_CAPACITY 指定,数值为 1<<30,也就是 2 的 30 次方),我们可以归纳为:
- 门限值等于(负载因子)x(容量),如果构建 HashMap 的时候没有指定它们,那么就是依据相应的默认常量值。
- 门限通常是以倍数进行调整 (newThr = oldThr << 1),我前面提到,根据 putVal 中的逻辑,当元素个数超过门限大小时,则调整 Map 大小。
- 扩容后,需要将老的数组中的元素重新放置到新的数组,这是扩容的一个主要开销来源。
容量(capacity)和负载因子(load factor)。
容量和负载系数决定了可用的桶的数量,空桶太多会浪费空间,如果使用的太满则会严重影响操作的性能。极端情况下,假设只有一个桶,那么它就退化成了链表,完全不能提供所谓常数时间存的性能。
如果能够知道 HashMap 要存取的键值对数量,可以考虑预先设置合适的容量大小。具体数值我们可以根据扩容发生的条件来做简单预估,根据前面的代码分析,我们知道它需要符合计算条件:
负载因子 * 容量 > 元素数量
负载因子:
如果没有特别需求,不要轻易进行更改,因为 JDK 自身的默认负载因子是非常符合通用场景的需求的。
如果确实需要调整,建议不要设置超过 0.75 的数值,因为会显著增加冲突,降低 HashMap 的性能。
如果使用太小的负载因子,按照上面的公式,预设容量值也进行调整,否则可能会导致更加频繁的扩容,增加无谓的开销,本身访问性能也会受影响。
树化
1 | final void treeifyBin(Node<K,V>[] tab, int hash) { |
上面是精简过的 treeifyBin 示意,综合这两个方法,树化改造的逻辑就非常清晰了,可以理解为,当 bin 的数量大于 TREEIFY_THRESHOLD 时:
- 如果容量小于 MIN_TREEIFY_CA PACITY,只会进行简单的扩容。
- 如果容量大于 MIN_TREEIFY_CAPACITY ,则会进行树化改造。
那么,为什么 HashMap 要树化呢?
本质上这是个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取的性能。
而在现实世界,构造哈希冲突的数据并不是非常复杂的事情,恶意代码就可以利用这些数据大量与服务器端交互,导致服务器端 CPU 大量占用,这就构成了哈希碰撞拒绝服务攻击,国内一线互联网公司就发生过类似攻击事件。
Tomcat,Apache,JBoss的区别?
1、Apache是Http服务器,Tomcat是web服务器,JBoss是应用服务器。
2、Apache解析静态的html文件;Tomcat可解析jsp动态页面、也可充当servlet容器。
https://foohsinglong.iteye.com/blog/1195780?spm=a2c4e.11153940.blogcont6656.5.3b4f791dTyQ4Sp
Session, Cookie区别
1、Session由应用服务器维护的一个服务器端的存储空间;Cookie是客户端的存储空间,由浏览器维护。
2、用户可以通过浏览器设置决定是否保存Cookie,而不能决定是否保存Session,因为Session是由服务器端维护的。
3、Session中保存的是对象,Cookie中保存的是字符串。
4、Session和Cookie不能跨窗口使用,每打开一个浏览器系统会赋予一个SessionID,此时的SessionID不同,若要完成跨浏览器访问数据,可以使用 Application。
5、Session、Cookie都有失效时间,过期后会自动删除,减少系统开销。
Statement与PreparedStatement的区别,什么是SQL注入,如何防止SQL注入
1、PreparedStatement支持动态设置参数,Statement不支持。
2、PreparedStatement可避免如类似 单引号 的编码麻烦,Statement不可以。
3、PreparedStatement支持预编译,Statement不支持。
4、在sql语句出错时PreparedStatement不易检查,而Statement则更便于查错。
5、PreparedStatement可防止Sql助于,更加安全,而Statement不行。
Servlet的生命周期
sendRedirect, foward区别
1、foward是服务器端控制页面转向,在客户端的浏览器地址中不会显示转向后的地址;sendRedirect则是完全的跳转,浏览器中会显示跳转的地址并重新发送请求链接。
原理:forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后再将这些内容返回给浏览器,浏览器根本不知道服务器发送的这些内容是从哪来的,所以地址栏还是原来的地址。
redirect是服务器端根据逻辑,发送一个状态码,告诉浏览器重新去请求的那个地址,浏览器会用刚才的所有参数重新发送新的请求。
操作系统中的monitors
管程(monitors)在操作系统中是很重要的概念,下面是管程的概念:
管程 (英语:Monitors,也称为监视器) 是一种程序结构,结构内的多个子程序(对象或模块)形成的多个工作线程互斥访问共享资源。这些共享资源一般是硬件设备或一群变量。管程实现了在一个时间点,最多只有一个线程在执行管程的某个子程序。与那些通过修改数据结构实现互斥访问的并发程序设计相比,管程实现很大程度上简化了程序设计。 管程提供了一种机制,线程可以临时放弃互斥访问,等待某些条件得到满足后,重新获得执行权恢复它的互斥访问。
JAVA中的monitor
monitor在java同步机制中使用。在多线程访问共享资源的时候,经常会带来可见性和原子性的安全问题。为了解决这类线程安全的问题,Java提供了同步机制、互斥锁机制,这个机制保证了在同一时刻只有一个线程能访问共享资源。这个机制的保障来源于监视锁Monitor,每个对象都拥有自己的监视锁Monitor。
监视器是一个用来监视这些线程进入特殊的房间的。他的义务是保证(同一时间)只有一个线程可以访问被保护的数据和代码。
Monitor其实是一种同步工具,也可以说是一种同步机制,它通常被描述为一个对象,主要特点是:
(1)对象的所有方法都被“互斥”的执行。好比一个Monitor只有一个运行“许可”,任一个线程进入任何一个方法都需要获得这个“许可”,离开时把许可归还。
(2)通常提供singnal机制:允许正持有“许可”的线程暂时放弃“许可”,等待某个谓词成真(条件变量),而条件成立后,当前进程可以“通知”正在等待这个条件变量的线程,让他可以重新去获得运行许可。
JAVA对象生命周期
https://www.cnblogs.com/mengfanrong/p/4007456.html
MYSQL explain
table
显示这一行的数据是关于哪张表的
type
这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL
possible_keys
显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key
实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句 中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len
使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
rows
MYSQL认为必须检查的用来返回请求数据的行数
Extra
关于MYSQL如何解析查询的额外信息。将在表4.3中讨论,但这里可以看到的坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢
长连接和短连接
但从 HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头有加入这行代码
Connection:keep-alive
正常情况下,一条TCP长连接建立后,只要双不提出关闭请求并且不出现异常情况,这条连接是一直存在的,操作系统不会自动去关闭它,甚至经过物理网络拓扑的改变之后仍然可以使用。所以一条连接保持几天、几个月、几年或者更长时间都有可能,只要不出现异常情况或由用户(应用层)主动关闭。
存在一个问题,存活功能的探测周期太长
DDOS
基于ARP
ARP是无连接的协议,当收到攻击者发送来的ARP应答时。它将接收ARP应答包中所提供的信息。更新ARP缓存。因此,含有错误源地址信息的ARP请求和含有错误目标地址信息的ARP应答均会使上层应用忙于处理这种异常而无法响应外来请求,使得目标主机丧失网络通信能力。产生拒绝服务,如ARP重定向攻击。
基于ICMP
攻击者向一个子网的广播地址发送多个ICMP Echo请求数据包。并将源地址伪装成想要攻击的目标主机的地址。这样,该子网上的所有主机均对此ICMP Echo请求包作出答复,向被攻击的目标主机发送数据包,使该主机受到攻击,导致网络阻塞。
基于IP
TCP/IP中的IP数据包在网络传递时,数据包可以分成更小的片段。到达目的地后再进行合并重装。在实现分段重新组装的进程中存在漏洞,缺乏必要的检查。利用IP报文分片后重组的重叠现象攻击服务器,进而引起服务器内核崩溃。如Teardrop是基于IP的攻击。
基于TCP
[2] SYN Flood攻击的过程在TCP协议中被称为三次握手(Three-way Handshake),而SYN Flood拒绝服务攻击就是通过三次握手而实现的。TCP连接的三次握手中,假设一个用户向服务器发送了SYN报文后突然死机或掉线,那么服务器在发出SYN+ACK应答报文后是无法收到客户端的ACK报文的(第三次握手无法完成),这种情况下服务器端一般会重试(再次发送SYN+ACK给客户端)并等待一段时间后丢弃这个未完成的连接。服务器端将为了维护一个非常大的半连接列表而消耗非常多的资源。
基于应用层
应用层包括SMTP,HTTP,DNS等各种应用协议。其中SMTP定义了如何在两个主机间传输邮件的过程,基于标准SMTP的邮件服务器,在客户端请求发送邮件时,是不对其身份进行验证的。另外,许多邮件服务器都允许邮件中继。攻击者利用邮件服务器持续不断地向攻击目标发送垃圾邮件,大量侵占服务器资源。
输入一个url,发生了什么事情
浏览器解析出url中的域名。
查询浏览器的DNS缓存。
浏览器中没有DNS缓存,则查找本地客户端hosts文件有无对应的ip地址。
hosts中无,则查找本地DNS服务器(运营商提供的DNS服务器)有无对应的DNS缓存。
若本地DNS没有DNS缓存,则向根服务器查询,进行递归查找。
递归查找从顶级域名开始(如.com),一步步缩小范围,最终客户端取得ip地址。
http协议建立在tcp协议之上,http请求前,需先进行tcp连接,形成客户端到服务器的稳定的通道。俗称TCP的三次握手。
tcp连接完成后,http请求开始,请求有多种方式,常见的有get,post等。
http请求包含请求头,也可能包含请求体两部分,请求头中包含我们希望对请求文件的操作的信息,请求体中包含传递给后台的参数。
服务器收到http请求后,后台开始工作,如负载平衡,跨域等,这里就是后端的工作了。
文件处理完毕,生成响应数据包,响应也包含两部分,响应头和相应体,响应体就是我们所请求的文件。
经过网络传输,文件被下载到本地客户端,客户端开始加载。
客户端浏览器加载了html文件后,由上到下解析html为DOM树(DOM Tree)。
遇到css文件,css中的url发起http请求。
这是第二次http请求,由于http1.1协议增加了Connection: keep-alive声明,故tcp连接不会关闭,可以复用。
http连接是无状态连接,客户端与服务器端需要重新发起请求–响应。
在请求css的过程中,解析器继续解析html,然后到了script标签。
由于script可能会改变DOM结构,故解析器停止生成DOM树,解析器被js阻塞,等待js文件发起http请求,然后加载。这是第三次http请求。js执行完成后解析器继续解析。
由于css文件可能会影响js文件的执行结果,因此需等css文件加载完成后再执行。
浏览器收到css文件后,开始解析css文件为CSSOM树(CSS Rule Tree)。
CSSOM树生成后,DOM Tree与CSS Rule Tree结合生成渲染树(Render Tree)。
Render Tree会被css文件阻塞,渲染树生成后,先布局,绘制渲染树中节点的属性(位置,宽度,大小等),然后渲染,页面就会呈现信息。
继续边解析边渲染,遇到了另一个js文件,js文件执行后改变了DOM树,渲染树从被改变的dom开始再次渲染。
继续向下渲染,碰到一个img标签,浏览器发起http请求,不会等待img加载完成,继续向下渲染,之后再重新渲染此部分。
DOM树遇到html结束标签,停止解析,进而渲染结束。
优化:
①减少DNS查询:将服务器域名的ip信息加入本地host文件。
②减少http请求数量,对于图片使用雪碧图,对于html文件和css文件,js文件分别进行合并操作。
③减少下载时间:压缩图片,使用压缩应用压缩文档中的空格,删除文件多余的语句和注释,创造自己的js精简库和精简框架,使用本地浏览器缓存。
④提前渲染开始时间:将css链接放在html头部。
⑤减轻解析器的阻塞:将js链接放在body尾部。
常见OOM
常见内存溢出错误解决办法
除了程序计数器外,虚拟机内存的其他几个运行时区域都有发生OutOfMemoryError(OOM)异常的可能,
1,Java Heap 溢出
一般的异常信息:java.lang.OutOfMemoryError:Java heap spacess
java堆用于存储对象实例,我们只要不断的创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,就会在对象数量达到最大堆容量限制后产生内存溢出异常。
出现这种异常,一般手段是先通过内存映像分析工具(如Eclipse Memory Analyzer)对dump出来的堆转存快照进行分析,重点是确认内存中的对象是否是必要的,先分清是因为内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。
如果是内存泄漏,可进一步通过工具(如Jrockit等工具)查看泄漏对象到GC Roots的引用链。于是就能找到泄漏对象时通过怎样的路径与GC Roots相关联并导致垃圾收集器无法自动回收。
如果不存在泄漏,那就应该检查虚拟机的参数(-Xmx与-Xms)的设置是否适当。
2,虚拟机栈和本地方法栈溢出
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。
如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常
这里需要注意当栈的大小越大可分配的线程数就越少。
3,运行时常量池溢出
异常信息:java.lang.OutOfMemoryError:PermGen space
如果要向运行时常量池中添加内容,最简单的做法就是使用String.intern()这个Native方法。该方法的作用是:如果池中已经包含一个等于此String的字符串,则返回代表池中这个字符串的String对象;否则,将此String对象包含的字符串添加到常量池中,并且返回此String对象的引用。由于常量池分配在方法区内,我们可以通过-XX:PermSize和-XX:MaxPermSize限制方法区的大小,从而间接限制其中常量池的容量。
4,方法区溢出
方法区用于存放Class的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。
异常信息:java.lang.OutOfMemoryError:PermGen space
方法区溢出也是一种常见的内存溢出异常,一个类如果要被垃圾收集器回收,判定条件是很苛刻的。在经常动态生成大量Class的应用中,要特别注意这点。
final、finally、 finalize有什么不同
final 可以用来修饰类、方法、变量,分别有不同的意义,final 修饰的 class 代表不可以继承扩展,final 的变量是不可以修改的,而 final 的方法也是不可以重写的(override)。
finally 则是 Java 保证重点代码一定要被执行的一种机制。我们可以使用 try-finally 或者 try-catch-finally 来进行类似关闭 JDBC 连接、保证 unlock 锁等动作。
特殊情况:
1 | try { |
finalize 是基础类 java.lang.Object 的一个方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收。finalize 机制现在已经不推荐使用,并且在 JDK 9 开始被标记为 deprecated。
Immutable 在很多场景是非常棒的选择,某种意义上说,Java 语言目前并没有原生的不可变支持,如果要实现 immutable 的类,我们需要做到:
- 将 class 自身声明为 final,这样别人就不能扩展来绕过限制了。
- 将所有成员变量定义为 private 和 final,并且不要实现 setter 方法。
- 通常构造对象时,成员变量使用深度拷贝来初始化,而不是直接赋值,这是一种防御措施,因为你无法确定输入对象不被其他人修改。
- 如果确实需要实现 getter 方法,或者其他可能会返回内部状态的方法,使用 copy-on-write 原则,创建私有的 copy。
什么是写时复制(Copy-On-Write)容器?
写时复制是指:在并发访问的情景下,当需要修改JAVA中Containers的元素时,不直接修改该容器,而是先复制一份副本,在副本上进行修改。修改完成之后,将指向原来容器的引用指向新的容器(副本容器)。
写时复制带来的影响
①由于不会修改原始容器,只修改副本容器。因此,可以对原始容器进行并发地读。其次,实现了读操作与写操作的分离,读操作发生在原始容器上,写操作发生在副本容器上。
②数据一致性问题:读操作的线程可能不会立即读取到新修改的数据,因为修改操作发生在副本上。但最终修改操作会完成并更新容器,因此这是最终一致性。
谈谈MySQL支持的事务隔离级别,以及悲观锁和乐观锁的原理和应用场景?
隔离级别:就是在数据库事务中,为保证并发数据读写的正确性而提出的定义,它并不是 MySQL 专有的概念,而是源于SQL-92标准。
InnoDB引擎:基于MVCC(Multi-Versioning Concurrency Control)和锁的复合实现,按照隔离程度从低到高,MySQL 事务隔离级别分为四个不同层次:
MVCC: 即多版本并发控制技术,它使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能
隔离级别:
读未提交: 一个事务能够看到其他尚未提交的修改,允许脏读的出现。
读已提交: 读已提交(Read committed),事务能够看到的数据都是其他事务已经提交的修改,也就是保证不会看到任何中间性状态,当然脏读也不会出现。读已提交仍然是比较低级别的隔离,并不保证再次读取时能够获取同样的数据,也就是允许其他事务并发修改数据,允许不可重复读和幻象读(Phantom Read)出现。
可重复读(默认):可重复读(Repeatable reads),保证同一个事务中多次读取的数据是一致的,这是 MySQL InnoDB 引擎的默认隔离级别,但是和一些其他数据库实现不同的是,可以简单认为 MySQL 在可重复读级别不会出现幻象读。
串行化: 串行化(Serializable),并发事务之间是串行化的,通常意味着读取需要获取共享读锁,更新需要获取排他写锁,如果 SQL 使用 WHERE 语句,还会获取区间锁(MySQL 以 GAP 锁形式实现,可重复读级别中默认也会使用),这是最高的隔离级别。
悲观锁和乐观锁,也并不是 MySQL 或者数据库中独有的概念,而是并发编程的基本概念。主要区别在于,操作共享数据时,“悲观锁”即认为数据出现冲突的可能性更大,而“乐观锁”则是认为大部分情况不会出现冲突,进而决定是否采取排他性措施。
MySQL 数据库应用开发中,悲观锁一般就是利用类似 SELECT … FOR UPDATE 这样的语句,对数据加锁,避免其他事务意外修改数据。乐观锁则与 Java 并发包中的 AtomicFieldUpdater 类似,也是利用 CAS 机制,并不会对数据加锁,而是通过对比数据的时间戳或者版本号,来实现乐观锁需要的版本判断。
CAS机制
synchronized关键字会让没有得到锁资源的线程进入BLOCKED状态,而后在争夺到锁资源后恢复为RUNNABLE状态,这个过程中涉及到操作系统用户模式和内核模式的转换,代价比较高。
尽管JAVA 1.6为synchronized做了优化,增加了从偏向锁到轻量级锁再到重量级锁的过过度,但是在最终转变为重量级锁之后,性能仍然比较低。所以面对这种情况,我们就可以使用java中的“原子操作类”。
所谓原子操作类,指的是java.util.concurrent.atomic包下,一系列以Atomic开头的包装类。如AtomicBoolean,AtomicUInteger,AtomicLong。它们分别用于Boolean,Integer,Long类型的原子性操作。
而Atomic操作类的底层正是用到了“CAS机制”。
CAS是英文单词Compare and Swap的缩写,翻译过来就是比较并替换。
CAS机制中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
synchronized属于悲观锁,悲观的认为程序中的并发情况严重,所以严防死守,CAS属于乐观锁,乐观地认为程序中的并发情况不那么严重,所以让线程不断去重试更新。
CAS的问题:
CAS的缺点:
1) CPU开销过大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很到的压力。
2) 不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用synchronized了。
3) ABA问题
*1. java语言CAS底层如何实现?
利用unsafe提供的原子性操作方法。
2.什么事ABA问题?怎么解决?
当一个值从A变成B,又更新回A,普通CAS机制会误判通过检测。
利用版本号比较可以有效解决ABA问题。**
前面提到的 MVCC,其本质就可以看作是种乐观锁机制,而排他性的读写锁、双阶段锁等则是悲观锁的实现。
Mybatis
mybatis架构自下而上分为基础支撑层、数据处理层、API接口层这三层。
基础支撑层,主要是用来做连接管理、事务管理、配置加载、缓存管理等最基础组件,为上层提供最基础的支撑。
数据处理层,主要是用来做参数映射、sql解析、sql执行、结果映射等处理,可以理解为请求到达,完成一次数据库操作的流程。
API接口层,主要对外提供API,提供诸如数据的增删改查、获取配置等接口。
强引用、软引用、弱引用、幻象引用有什么区别?具体使用场景是什么
不同的引用类型,主要体现的是对象不同的可达性(reachable)状态和对垃圾收集的影响
强引用(“Strong” Reference),就是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾收集器不会碰这种对象。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为 null,就是可以被垃圾收集的了,当然具体回收时机还是要看垃圾收集策略。
软引用(SoftReference),是一种相对强引用弱化一些的引用,可以让对象豁免一些垃圾收集,只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象。JVM 会确保在抛出 OutOfMemoryError 之前,清理软引用指向的对象。软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
弱引用(WeakReference)并不能使对象豁免垃圾收集,仅仅是提供一种访问在弱引用状态下对象的途径。这就可以用来构建一种没有特定约束的关系,比如,维护一种非强制性的映射关系,如果试图获取时对象还在,就使用它,否则重现实例化。它同样是很多缓存实现的选择。
幻象引用,有时候也翻译成虚引用,你不能通过它访问对象。幻象引用仅仅是提供了一种确保对象被 finalize 以后,做某些事情的机制,比如,通常用来做所谓的 Post-Mortem 清理机制,也有人利用幻象引用监控对象的创建和销毁。
简易对象生命周期:
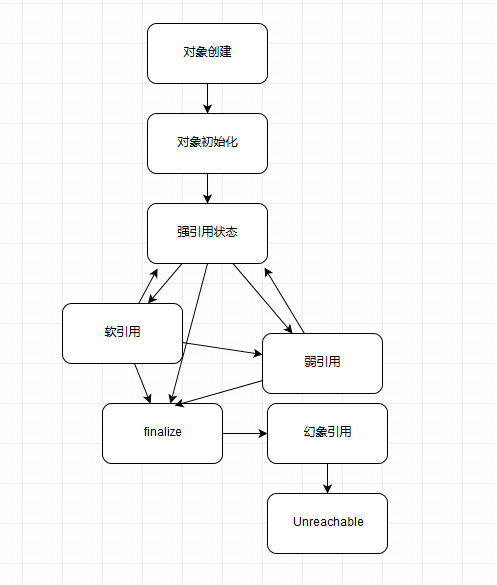
强可达(Strongly Reachable),就是当一个对象可以有一个或多个线程可以不通过各种引用访问到的情况。比如,我们新创建一个对象,那么创建它的线程对它就是强可达。
软可达(Softly Reachable),就是当我们只能通过软引用才能访问到对象的状态。
弱可达(Weakly Reachable),类似前面提到的,就是无法通过强引用或者软引用访问,只能通过弱引用访问时的状态。这是十分临近 finalize 状态的时机,当弱引用被清除的时候,就符合 finalize 的条件了。
幻象可达(Phantom Reachable),上面流程图已经很直观了,就是没有强、软、弱引用关联,并且 finalize 过了,只有幻象引用指向这个对象的时候。
不可达(unreachable),意味着对象可以被清除了。
所有引用类型,都是抽象类 java.lang.ref.Reference 的子类,你可能注意到它提供了 get() 方法:除了幻象引用(因为 get 永远返回 null),如果对象还没有被销毁,都可以通过 get 方法获取原有对象。这意味着,利用软引用和弱引用,我们可以将访问到的对象,重新指向强引用,也就是人为的改变了对象的可达性状态!这也是为什么上面图里有些地方画了双向箭头。
引用队列:
谈到各种引用的编程,就必然要提到引用队列。我们在创建各种引用并关联到响应对象时,可以选择是否需要关联引用队列,JVM 会在特定时机将引用 enqueue 到队列里,我们可以从队列里获取引用(remove 方法在这里实际是有获取的意思)进行相关后续逻辑。尤其是幻象引用,get 方法只返回 null,如果再不指定引用队列,基本就没有意义了。看看下面的示例代码。利用引用队列,我们可以在对象处于相应状态时(对于幻象引用,就是前面说的被 finalize 了,处于幻象可达状态),执行后期处理逻辑。
显式地影响软引用垃圾收集
诊断JVM引用情况:
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintReferenceGC
JDK 8 使用 ParrallelGC 收集的垃圾收集日志,各种引用数量非常清晰。
注意:JDK 9 对 JVM 和垃圾收集日志进行了广泛的重构,,类似 PrintGCTimeStamps 和 PrintReferenceGC 已经不再存在,我在专栏后面的垃圾收集主题里会更加系统的阐述。
Reachability Fence
可以通过底层 API 来达到强引用的效果,这就是所谓的设置Reachability Fence,new Resource().action()类似的链式diaoy9ong,因为没有强引用指向Resource对象,JVM对它进行finalize操作是完全合法的。这时候,可以在finally里边明确保障对象Reference.reachabilityFence(this)。
TCP/IP

动态代理是基于什么原理
反射机制是 Java 语言提供的一种基础功能,赋予程序在运行时(introspect,官方用语)的能力。通过反射我们可以直接操作类或者对象,比如获取某个对象的类定义,获取类声明的属性和方法,调用方法或者构造对象,甚至可以运行时修改类定义。
动态代理是一种方便运行时动态构建代理、动态处理代理方法调用的机制,很多场景都是利用类似机制做到的,比如用来包装 RPC 调用、面向切面的编程(AOP)。
实现动态代理的方式很多,比如 JDK 自身提供的动态代理,就是主要利用了上面提到的反射机制。还有其他的实现方式,比如利用传说中更高性能的字节码操作机制,类似 ASM、cglib(基于 ASM)、Javassist 等。
代理类在程序运行时创建的代理方式被成为动态代理。 我们上面静态代理的例子中,代理类(studentProxy)是自己定义好的,在程序运行之前就已经编译完成。然而动态代理,代理类并不是在Java代码中定义的,而是在运行时根据我们在Java代码中的“指示”动态生成的。相比于静态代理, 动态代理的优势在于可以很方便的对代理类的函数进行统一的处理,而不用修改每个代理类中的方法。 比如说,想要在每个代理的方法前都加上一个处理方法。

关于反射,有一点我需要特意提一下,就是反射提供的 AccessibleObject.setAccessible(boolean flag)。它的子类也大都重写了这个方法,这里的所谓 accessible 可以理解成修饰成员的 public、protected、private,这意味着我们可以在运行时修改成员访问限制!
反射使用场景: AOP, lombok, ide 智能提示
因为反射机制使用广泛,目前,Java 9 仍然保留了兼容 Java 8 的行为,但是很有可能在未来版本,完全启用前面提到的针对 setAccessible 的限制,即只有当被反射操作的模块和指定的包对反射调用者模块 Open,才能使用 setAccessible,我们可以使用下面参数显式设置。
1 | public class MyDynamicProxy { |
如果被调用者没有实现接口,而我们还是希望利用动态代理机制,那么可以考虑其他方式。 Spring AOP 支持两种模式的动态代理,JDK Proxy 或者 cglib,如果我们选择 cglib 方式,对接口的依赖就会被克服了。
cglib 动态代理采取的是创建目标类的子类的方式,因为是子类化,我们可以达到近似使用被调用者本身的效果。在 Spring 编程中,框架通常会处理这种情况。
JDK Proxy 的优势:
最小化依赖关系,减少依赖意味着简化开发和维护,JDK 本身的支持,可能比 cglib 更加可靠。
平滑进行 JDK 版本升级,而字节码类库通常需要进行更新以保证在新版 Java 上能够使用。
- 代码实现简单。
基于类似 cglib 框架的优势:
- 有的时候调用目标可能不便实现额外接口,从某种角度看,限定调用者实现接口是有些侵入性的实践,类似 cglib 动态代理就没有这种限制。
- 只操作我们关心的类,而不必为其他相关类增加工作量。
- 高性能
int 和 Integer 有什么区别?谈谈 Integer的缓存范围
int 是我们常说的整形数字,是 Java 的 8 个原始数据类型(Primitive Types,boolean、byte 、short、char、int、float、double、long)之一。Java 语言虽然号称一切都是对象,但原始数据类型是例外。
Integer 是 int 对应的包装类,它有一个 int 类型的字段存储数据,并且提供了基本操作,比如数学运算、int 和字符串之间转换等。在 Java 5 中,引入了自动装箱和自动拆箱功能(boxing/unboxing),Java 可以根据上下文,自动进行转换,极大地简化了相关编程。
关于 Integer 的值缓存,这涉及 Java 5 中另一个改进。构建 Integer 对象的传统方式是直接调用构造器,直接 new 一个对象。但是根据实践,我们发现大部分数据操作都是集中在有限的、较小的数值范围,因而,在 Java 5 中新增了静态工厂方法 valueOf,在调用它的时候会利用一个缓存机制,带来了明显的性能改进。按照 Javadoc,默认缓存是-128到127之间。
自动装箱实际上算是一种语法糖。可以简单理解为 Java 平台为我们自动进行了一些转换,保证不同的写法在运行时等价,它们发生在编译阶段,也就是生成的字节码是一致的。
像前面提到的整数,javac 替我们自动把装箱转换为 Integer.valueOf(),把拆箱替换为 Integer.intValue(),这似乎这也顺道回答了另一个问题,既然调用的是 Integer.valueOf,自然能够得到缓存的好处啊。
- Boolean,缓存了 true/false 对应实例,确切说,只会返回两个常量实例 Boolean.TRUE/FALSE。
- Short,同样是缓存了 -128 到 127 之间的数值。
- Byte,数值有限,所以全部都被缓存。
- Character,缓存范围’\u0000’ 到 ‘\u007F’。
建议避免无意中的装箱、拆箱行为
缓存上限值实际是可以根据需要调整的,JVM 提供了参数设置:
-XX:AutoBoxCacheMax=N
如何保证集合是线程安全的? ConcurrentHashMap如何实现高效地线程安全?
Java 提供了不同层面的线程安全支持。在传统集合框架内部,除了 Hashtable 等同步容器,还提供了所谓的同步包装器(Synchronized Wrapper),我们可以调用 Collections 工具类提供的包装方法,来获取一个同步的包装容器(如 Collections.synchronizedMap),但是它们都是利用非常粗粒度的同步方式,在高并发情况下,性能比较低下。
- 各种并发容器,比如 ConcurrentHashMap、CopyOnWriteArrayList。
- 各种线程安全队列(Queue/Deque),如 ArrayBlockingQueue、SynchronousQueue。
- 各种有序容器的线程安全版本等。
具体保证线程安全的方式,包括有从简单的 synchronize 方式,到基于更加精细化的,比如基于分离锁实现的 ConcurrentHashMap 等并发实现等。具体选择要看开发的场景需求,总体来说,并发包内提供的容器通用场景,远优于早期的简单同步实现。
- 理解基本的线程安全工具。
理解传统集合框架并发编程中 Map 存在的问题,清楚简单同步方式的不足。
梳理并发包内,尤其是 ConcurrentHashMap 采取了哪些方法来提高并发表现。
- 最好能够掌握 ConcurrentHashMap 自身的演进,目前的很多分析资料还是基于其早期版本。
为什么需要ConcureentHashMap?
Hashtable 本身比较低效,因为它的实现基本就是将 put、get、size 等各种方法加上“synchronized”。简单来说,这就导致了所有并发操作都要竞争同一把锁,一个线程在进行同步操作时,其他线程只能等待,大大降低了并发操作的效率。
前面已经提过 HashMap 不是线程安全的,并发情况会导致类似 CPU 占用 100% 等一些问题,那么能不能利用 Collections 提供的同步包装器来解决问题呢?
看看下面的代码片段,我们发现同步包装器只是利用输入 Map 构造了另一个同步版本,所有操作虽然不再声明成为 synchronized 方法,但是还是利用了“this”作为互斥的 mutex,没有真正意义上的改进!
1 | private static class SynchronizedMap<K,V> |
所以,Hashtable 或者同步包装版本,都只是适合在非高度并发的场景下。
ConcurrentHashMap 是如何设计实现的,为什么它能大大提高并发效率。
ConcurrentHashMap 的设计实现其实一直在演化:,比如在 Java 8 中就发生了非常大的变化(Java 7 其实也有不少更新),所以,我这里将比较分析结构、实现机制等方面,对比不同版本的主要区别。
早期 ConcurrentHashMap,其实现是基于:
分离锁,也就是将内部进行分段(Segment),里面则是 HashEntry 的数组,和 HashMap 类似,哈希相同的条目也是以链表形式存放。
HashEntry 内部使用 volatile 的 value 字段来保证可见性,也利用了不可变对象的机制以改进利用 Unsafe 提供的底层能力,比如 volatile access,去直接完成部分操作,以最优化性能,毕竟 Unsafe 中的很多操作都是 JVM intrinsic 优化过的。
参考下面这个早期 ConcurrentHashMap 内部结构的示意图,其核心是利用分段设计,在进行并发操作的时候,只需要锁定相应段,这样就有效避免了类似 Hashtable 整体同步的问题,大大提高了性能。
在构造的时候,Segment 的数量由所谓的 concurrentcyLevel 决定,默认是 16,也可以在相应构造函数直接指定。注意,Java 需要它是 2 的幂数值,如果输入是类似 15 这种非幂值,会被自动调整到 16 之类 2 的幂数值。
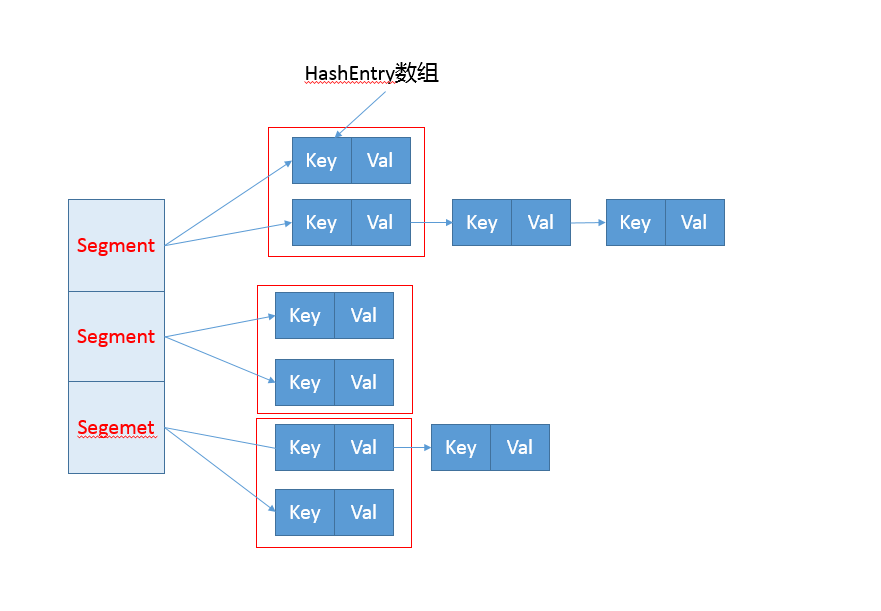
get操作:
1 | public V get(Object key) { |
put操作:首先是通过二次哈希避免哈希冲突,然后以 Unsafe 调用方式,直接获取相应的 Segment,然后进行线程安全的 put 操作:
1 | public V put(K key, V value) { |
- ConcurrentHashMap 会获取再入锁(重入锁(ReentrantLock)是一种递归无阻塞的同步机制),以保证数据一致性,Segment 本身就是基于 ReentrantLock 的扩展实现,所以,在并发修改期间,相应 Segment 是被锁定的。
- 在最初阶段,进行重复性的扫描,以确定相应 key 值是否已经在数组里面,进而决定是更新还是放置操作。重复扫描、检测冲突是 ConcurrentHashMap 的常见技巧。
- 扩容问题在 ConcurrentHashMap 中同样存在。不过有一个明显区别,就是它进行的不是整体的扩容,而是单独对 Segment 进行扩容。
另外一个 Map 的 size 方法同样需要关注,它的实现涉及分离锁的一个副作用。如果不进行同步,简单的计算所有 Segment 的总值,可能会因为并发 put,导致结果不准确,但是直接锁定所有 Segment 进行计算,就会变得非常昂贵。其实,分离锁也限制了 Map 的初始化等操作。所以,ConcurrentHashMap 的实现是通过重试机制(RETRIES_BEFORE_LOCK,指定重试次数 2),来试图获得可靠值。如果没有监控到发生变化(通过对比 Segment.modCount),就直接返回,否则获取锁进行操作。
JAVA8和之后的版本:
- 总体结构上,它的内部存储变得和 HashMap 结构非常相似,同样是大的桶(bucket)数组,然后内部也是一个个所谓的链表结构(bin),同步的粒度要更细致一些。
- 其内部仍然有 Segment 定义,但仅仅是为了保证序列化时的兼容性而已,不再有任何结构上的用处。
- 因为不再使用 Segment,初始化操作大大简化,修改为 lazy-load 形式,这样可以有效避免初始开销,解决了老版本很多人抱怨的这一点。
- 数据存储利用 volatile 来保证可见性。
- 使用 CAS 等操作,在特定场景进行无锁并发操作。
- 使用 Unsafe、LongAdder 之类底层手段,进行极端情况的优化。
Rabbitmq
1. 如何确保消息正确地发送至RabbitMQ?
RabbitMQ使用发送方确认模式,确保消息正确地发送到RabbitMQ。
发送方确认模式:将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(not acknowledged,未确认)消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
2. 如何确保消息接收方消费了消息?
接收方消息确认机制:消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。
这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。
下面罗列几种特殊情况:
- 如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ会认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消息重复消费的隐患,需要根据bizId去重)
- 如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认为该消费者繁忙,将不会给该消费者分发更多的消息。
3. 如何避免消息重复投递或重复消费?
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重和幂等的依据(消息投递失败并重传),避免重复的消息进入队列;在消息消费时,要求消息体中必须要有一个bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID等)作为去重和幂等的依据,避免同一条消息被重复消费。
4. 消息基于什么传输?
由于TCP连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ使用信道的方式来传输数据。信道是建立在真实的TCP连接内的虚拟连接,且每条TCP连接上的信道数量没有限制。
5. 消息如何分发?
若该队列至少有一个消费者订阅,消息将以循环(round-robin)的方式发送给消费者。每条消息只会分发给一个订阅的消费者(前提是消费者能够正常处理消息并进行确认)。
6. 消息怎么路由?
消息路由必须有三部分:交换器、路由、绑定。生产者把消息发布到交换器上;绑定决定了消息如何从路由器路由到特定的队列;消息最终到达队列,并被消费者接收。
交换器本质是一张路由查询表(名称和队列id,类似于hash表),这是一个虚拟出来的东西,并不存在真实的交换器。
消息的生命周期:生产者生产消息A 交由信道,信道通过消息(消息由载体和标签)的标签(路由键)放到交换器发送到队列上(其实就是查询匹配,一旦匹配到了规则,信道就直接和队列产生连接,然后将消息发送过去)
- 消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。
- 通过队列路由键,可以把队列绑定到交换器上。
- 消息到达交换器后,RabbitMQ会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则)。如果能够匹配到队列,则消息会投递到相应队列中;如果不能匹配到任何队列,消息将进入 “黑洞”。
常用的交换器主要分为一下三种:
direct:1:1 如果路由键完全匹配,消息就被投递到相应的队列
fanout:1:N 如果交换器收到消息,将会广播到所有绑定的队列上
ps:这个可以在业务上实现并行处理多个任务,比如,用户上传图片功能,当消息到达交换器上,它可以同时路由到积分增加队列和其它队列上,达到并行处理的目的,并且易扩展,以后有什么并行任务的时候,直接绑定到fanout交换器不需求改动之前的代码。
topic:N: 1 可以使来自不同源头的消息能够到达同一个队列。 使用topic交换器时,可以使用通配符,比如:“*” 匹配特定位置的任意文本, “.” 把路由键分为了几部分,“#” 匹配所有规则等。特别注意:发往topic交换器的消息不能随意的设置选择键(routing_key),必须是由”.”隔开的一系列的标识符组成。
7. 如何确保消息不丢失?
消息持久化的前提是:将交换器/队列的durable属性设置为true,表示交换器/队列是持久交换器/队列,在服务器崩溃或重启之后不需要重新创建交换器/队列(交换器/队列会自动创建)。
如果消息想要从Rabbit崩溃中恢复,那么消息必须:
- 在消息发布前,通过把它的 “投递模式” 选项设置为2(持久)来把消息标记成持久化
- 将消息发送到持久交换器
- 消息到达持久队列
RabbitMQ确保持久性消息能从服务器重启中恢复的方式是,将它们写入磁盘上的一个持久化日志文件,当发布一条持久性消息到持久交换器上时,Rabbit会在消息提交到日志文件后才发送响应(如果消息路由到了非持久队列,它会自动从持久化日志中移除)。一旦消费者从持久队列中消费了一条持久化消息,RabbitMQ会在持久化日志中把这条消息标记为等待垃圾收集。如果持久化消息在被消费之前RabbitMQ重启,那么Rabbit会自动重建交换器和队列(以及绑定),并重播持久化日志文件中的消息到合适的队列或者交换器上。
8. 使用RabbitMQ有什么好处?
- 应用解耦(系统拆分)
- 异步处理(预约挂号业务处理成功后,异步发送短信、推送消息、日志记录等)
- 消息分发
- 流量削峰
- 消息缓冲
RabbitMQ是 消息投递服务,在应用程序和服务器之间扮演路由器的角色,而应用程序或服务器可以发送和接收包裹。其通信方式是一种 “发后即忘(fire-and-forget)” 的单向方式。
9.消息丢失怎么办?
就是 RabbitMQ 自己弄丢了数据,这个你必须开启 RabbitMQ 的持久化,就是消息写入之后会持久化到磁盘,哪怕是 RabbitMQ 自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,RabbitMQ 还没持久化,自己就挂了,可能导致少量数据丢失,但是这个概率较小。
设置持久化有两个步骤:
创建 queue 的时候将其设置为持久化
这样就可以保证 RabbitMQ 持久化 queue 的元数据,但是它是不会持久化 queue 里的数据的。
第二个是发送消息的时候将消息的 deliveryMode 设置为 2
就是将消息设置为持久化的,此时 RabbitMQ 就会将消息持久化到磁盘上去。
必须要同时设置这两个持久化才行,RabbitMQ 哪怕是挂了,再次重启,也会从磁盘上重启恢复 queue,恢复这个 queue 里的数据。
注意,哪怕是你给 RabbitMQ 开启了持久化机制,也有一种可能,就是这个消息写到了 RabbitMQ 中,但是还没来得及持久化到磁盘上,结果不巧,此时 RabbitMQ 挂了,就会导致内存里的一点点数据丢失。
所以,持久化可以跟生产者那边的 confirm 机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者 ack 了,所以哪怕是在持久化到磁盘之前,RabbitMQ 挂了,数据丢了,生产者收不到 ack,你也是可以自己重发的。
REDIS
使用redis有哪些好处?
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
2. redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多 (3) redis可以持久化其数据
- Memcache与Redis的区别都有哪些?
1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,这样能保证数据的持久性。
2)、数据支持类型 Memcache对数据类型支持相对简单。 Redis有复杂的数据类型。
3)、使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
- redis常见性能问题和解决方案:
1).Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
2).Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
3).Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
4). Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
- .redis的并发竞争问题如何解决?
Redis为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis本身没有锁的概念,Redis对于多个客户端连接并不存在竞争,但是在Jedis客户端对Redis进行并发访问时会发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。对此有2种解决方法:
1.客户端角度,为保证每个客户端间正常有序与Redis进行通信,对连接进行池化,同时对客户端读写Redis操作采用内部锁synchronized。
2.服务器角度,利用setnx实现锁。
注:对于第一种,需要应用程序自己处理资源的同步,可以使用的方法比较通俗,可以使用synchronized也可以使用lock;第二种需要用到Redis的setnx命令,但是需要注意一些问题。
Redis支持的数据类型?
String字符串:
格式: set key value
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
Hash(哈希)
格式: hmset name key1 value1 key2 value2
Redis hash 是一个键值(key=>value)对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
格式: lpush name value
在 key 对应 list 的头部添加字符串元素
格式: rpush name value
在 key 对应 list 的尾部添加字符串元素
格式: lrem name index
key 对应 list 中删除 count 个和 value 相同的元素
格式: llen name
返回 key 对应 list 的长度
Set(集合)
格式: sadd name value
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
zset(sorted set:有序集合)
格式: zadd name score value
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
什么是Redis持久化?Redis有哪几种持久化方式?优缺点是什么?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 提供了两种持久化方式:RDB(默认) 和AOF
RDB:
(Redis DataBase)功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数
AOF:
Aof是Append-only file缩写,每当执行服务器(定时)任务或者函数时flushAppendOnlyFile 函数都会被调用, 这个函数执行以下两个工作
aof写入保存:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
存储结构:
内容是redis通讯协议(RESP )格式的命令文本存储。
什么是RESP?有什么特点?
RESP 是redis客户端和服务端之前使用的一种通讯协议;
RESP 的特点:实现简单、快速解析、可读性好
For Simple Strings the first byte of the reply is “+” 回复
For Errors the first byte of the reply is “-“ 错误
For Integers the first byte of the reply is “:” 整数
For Bulk Strings the first byte of the reply is “$” 字符串
For Arrays the first byte of the reply is “*” 数组
Redis 有哪些架构模式?讲讲各自的特点
单机
特点:简单
问题:
1、内存容量有限 2、处理能力有限 3、无法高可用。
主从复制
Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
特点:
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力在转交从库
问题:
无法保证高可用
没有解决 master 写的压力
哨兵
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
缺点:主从模式,切换需要时间丢数据, 没有解决 master 写的压力
集群(proxy 型):
Twemproxy 是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器; Twemproxy 是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
特点:1、多种 hash 算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins
2、支持失败节点自动删除
3、后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致
缺点:增加了新的 proxy,需要维护其高可用。
failover 逻辑需要自己实现,其本身不能支持故障的自动转移可扩展性差,进行扩缩容都需要手动干预
集群(直连型)
从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
特点:
1、无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
2、数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
3、可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
4、高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
5、实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升。
缺点:
1、资源隔离性较差,容易出现相互影响的情况。
2、数据通过异步复制,不保证数据的强一致性
什么是缓存穿透?如何避免?什么是缓存雪崩?何如避免?
缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免?
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
如何避免?
1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
2:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
3:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
使用过Redis分布式锁么,它是怎么实现的?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
,这个锁就永远得不到释放了。紧接着你需要抓一抓自己得脑袋,故作思考片刻,好像接下来的结果是你主动思考出来的,然后回答:我记得set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来用的!
set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来 用的!
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
Java提供了哪些IO方式? NIO如何实现多路复用?
Java IO 方式有很多种,基于不同的 IO 抽象模型和交互方式,可以进行简单区分。
首先,传统的 java.io 包,它基于流模型实现,提供了我们最熟知的一些 IO 功能,比如 File 抽象、输入输出流等。交互方式是同步、阻塞的方式,也就是说,在读取输入流或者写入输出流时,在读、写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。
java.io 包的好处是代码比较简单、直观,缺点则是 IO 效率和扩展性存在局限性,容易成为应用性能的瓶颈。
很多时候,人们也把 java.net 下面提供的部分网络 API,比如 Socket、ServerSocket、HttpURLConnection 也归类到同步阻塞 IO 类库,因为网络通信同样是 IO 行为。
第二,在 Java 1.4 中引入了 NIO 框架(java.nio 包),提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层的高性能数据操作方式。
第三,在 Java 7 中,NIO 有了进一步的改进,也就是 NIO 2,引入了异步非阻塞 IO 方式,也有很多人叫它 AIO(Asynchronous IO)。异步 IO 操作基于事件和回调机制,可以简单理解为,应用操作直接返回,而不会阻塞在那里,当后台处理完成,操作系统会通知相应线程进行后续工作。
JAVA内存模型
讲得非常详细:https://mp.weixin.qq.com/s/A_NgMZQeIf3_lU7AdimzYQ
JMM具备一些先天的有序性,即不需要通过任何手段就可以保证的有序性,通常称为happens-before原则。<<JSR-133:Java Memory Model and Thread Specification>>定义了如下happens-before规则:
1.程序顺序规则: 一个线程中的每个操作,happens-before于该线程中的任意后续操作
2.监视器锁规则:对一个线程的解锁,happens-before于随后对这个线程的加锁
3.volatile变量规则: 对一个volatile域的写,happens-before于后续对这个volatile域的读
4.传递性:如果A happens-before B ,且 B happens-before C, 那么 A happens-before C
5.start()规则: 如果线程A执行操作ThreadB_start()(启动线程B) , 那么A线程的ThreadB_start()happens-before 于B中的任意操作
6.join()原则: 如果A执行ThreadB.join()并且成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
7.interrupt()原则: 对线程interrupt()方法的调用先行发生于被中断线程代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测是否有中断发生
8.finalize()原则:一个对象的初始化完成先行发生于它的finalize()方法的开始
第1条规则程序顺序规则是说在一个线程里,所有的操作都是按顺序的,但是在JMM里其实只要执行结果一样,是允许重排序的,这边的happens-before强调的重点也是单线程执行结果的正确性,但是无法保证多线程也是如此。
第2条规则监视器规则其实也好理解,就是在加锁之前,确定这个锁之前已经被释放了,才能继续加锁。
第3条规则,就适用到所讨论的volatile,如果一个线程先去写一个变量,另外一个线程再去读,那么写入操作一定在读操作之前。
第4条规则,就是happens-before的传递性。
Synchronized底层实现
先看着,面试完了,动手实践一下
https://mp.weixin.qq.com/s/twINQA2k8OeaEmWjADiUmQ
传统的锁(也就是下文要说的重量级锁)依赖于系统的同步函数,在linux上使用mutex互斥锁,最底层实现依赖于futex,这些同步函数都涉及到用户态和内核态的切换、进程的上下文切换,成本较高。对于加了synchronized关键字但运行时并没有多线程竞争,或两个线程接近于交替执行的情况,使用传统锁机制无疑效率是会比较低的。
延伸:
Linux内核互斥锁-mutexLinux内核互斥锁–mutex
Linux Futex的设计与实现 感觉相当复杂
Futex是一种用户态和内核态混合的同步机制。首先,同步的进程间通过mmap共享一段内存,futex变量就 位于这段共享 的内存中且操作是原子的,当进程尝试进入互斥区或者退出互斥区的时候,先去查看共享内存中的futex变量,如果没有竞争发生,则只修改futex,而不 用再执行系统调用了。当通过访问futex变量告诉进程有竞争发生,则还是得执行系统调用去完成相应的处理(wait 或者 wake up)。简单的说,futex就是通过在用户态的检查,(motivation)如果了解到没有竞争就不用陷入内核了,大大提高了low-contention时候的效率。 Linux从2.5.7开始支持Futex。
在JDK 1.6之前,synchronized只有传统的锁机制,因此给开发者留下了synchronized关键字相比于其他同步机制性能不好的印象。
在JDK 1.6引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下因使用传统锁机制带来的性能开销问题。
Java并发编程:线程池的使用
如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间。
在Java中可以通过线程池来达到这样的效果。今天我们就来详细讲解一下Java的线程池,首先我们从最核心的ThreadPoolExecutor类中的方法讲起。
java.uitl.concurrent.ThreadPoolExecutor类是线程池中最核心的一个类,因此如果要透彻地了解Java中的线程池,必须先了解这个类。
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
下面解释下一下构造器中各个参数的含义:
corePoolSize:核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
unit:参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
1
2
3
4
5
6
7TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒workQueue:一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:
1
2
3ArrayBlockingQueue;
LinkedBlockingQueue;
SynchronousQueue;ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。
- threadFactory:线程工厂,主要用来创建线程;
- handler:表示当拒绝处理任务时的策略,有以下四种取值:
1
2
3
4ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
TCP 和 UDP 的区别
https://blog.csdn.net/zhang6223284/article/details/81414149
UDP
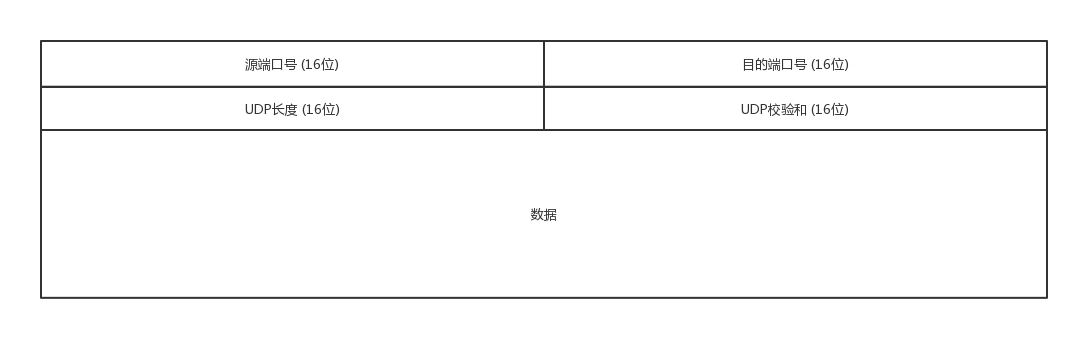
- 沟通简单,不需要大量的数据结构,处理逻辑和包头字段
- 它不会建立连接,但是会监听这个地方,谁都可以传给它数据,它也可以传给任何人数据,甚至可以同时传给多个人数据。
- 不会根据网络的情况进行拥塞控制,无论是否丢包,它该怎么发还是怎么发
应用场景:
- 需要资源少,网络情况稳定的内网,或者对于丢包不敏感的应用,比如 DHCP 就是基于 UDP 协议的。
不需要一对一沟通,建立连接,而是可以广播的应用。因为它不面向连接,所以可以做到一对多,承担广播或者多播的协议。
需要处理速度快,可以容忍丢包,但是即使网络拥塞,也毫不退缩,一往无前的时候
具体案例
- 直播。直播对实时性的要求比较高,宁可丢包,也不要卡顿的,所以很多直播应用都基于 UDP 实现了自己的视频传输协议
实时游戏。游戏的特点也是实时性比较高,在这种情况下,采用自定义的可靠的 UDP 协议,自定义重传策略,能够把产生的延迟降到最低,减少网络问题对游戏造成的影响
物联网。一方面,物联网领域中断资源少,很可能知识个很小的嵌入式系统,而维护 TCP 协议的代价太大了;另一方面,物联网对实时性的要求也特别高。比如 Google 旗下的 Nest 简历 Thread Group,推出了物联网通信协议 Thread,就是基于 UDP 协议的
TCP
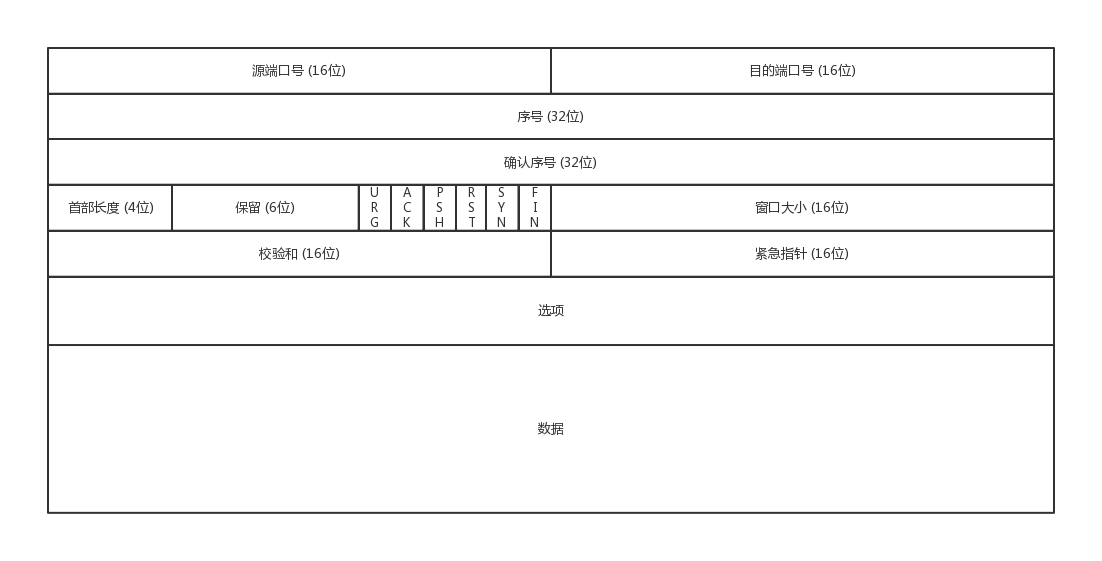
- 首先,源端口和目标端口是不可少的。
- 接下来是包的序号。主要是为了解决乱序问题。不编好号怎么知道哪个先来,哪个后到
确认序号。发出去的包应该有确认,这样能知道对方是否收到,如果没收到就应该重新发送,这个解决的是不丢包的问题 状态位。SYN 是发起一个链接,ACK 是回复,RST 是重新连接,FIN 是结束连接。因为 TCP 是面向连接的,因此需要双方维护连接的状态,这些状态位的包会引起双方的状态变更
窗口大小,TCP 要做流量控制,需要通信双方各声明一个窗口,标识自己当前的处理能力
通过对 TCP 头的解析,我们知道要掌握 TCP 协议,应该重点关注以下问题:
- 顺序问题
- 丢包问题
- 连接维护
- 流量控制
- 拥塞控制
TCP 3次握手
只需要3次握手:
在《计算机网络》一书中其中有提到,三次握手的目的是“为了防止已经失效的连接请求报文段突然又传到服务端,因而产生错误”,这种情况是:一端(client)A发出去的第一个连接请求报文并没有丢失,而是因为某些未知的原因在某个网络节点上发生滞留,导致延迟到连接释放以后的某个时间才到达另一端(server)B。本来这是一个早已失效的报文段,但是B收到此失效的报文之后,会误认为是A再次发出的一个新的连接请求,于是B端就向A又发出确认报文,表示同意建立连接。如果不采用“三次握手”,那么只要B端发出确认报文就会认为新的连接已经建立了,但是A端并没有发出建立连接的请求,因此不会去向B端发送数据,B端没有收到数据就会一直等待,这样B端就会白白浪费掉很多资源。如果采用“三次握手”的话就不会出现这种情况,B端收到一个过时失效的报文段之后,向A端发出确认,此时A并没有要求建立连接,所以就不会向B端发送确认,这个时候B端也能够知道连接没有建立。
简单理解:
1 | A:您好,我是 A |
在三次握手之后,A和B都能确定这么一件事: 我说的话,你能听到; 你说的话,我也能听到。 这样,就可以开始正常通信了。
注意: HTTP是基于TCP协议的,所以每次都是客户端发送请求,服务器应答,但是TCP还可以给其他应用层提供服务,即可能A、B在建立链接之后,谁都可能先开始通信。
如果两次,那么B无法确定B的信息A是否能收到,所以如果B先说话,可能后面的A都收不到,会出现问题 。
如果四次,那么就造成了浪费,因为在三次结束之后,就已经可以保证A可以给B发信息,A可以收到B的信息; B可以给A发信息,B可以收到A的信息。
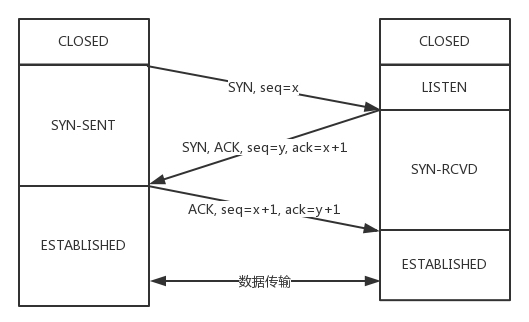
SYN攻击
在三次握手过程中,服务器发送SYN-ACK之后,收到客户端的ACK之前的TCP连接称为半连接(half-open connect).此时服务器处于Syn_RECV状态.当收到ACK后,服务器转入ESTABLISHED状态.
Syn攻击就是 攻击客户端 在短时间内伪造大量不存在的IP地址,向服务器不断地发送syn包,服务器回复确认包,并等待客户的确认,由于源地址是不存在的,服务器需要不断的重发直 至超时,这些伪造的SYN包将长时间占用未连接队列,正常的SYN请求被丢弃,目标系统运行缓慢,严重者引起网络堵塞甚至系统瘫痪。
Syn攻击是一个典型的DDOS攻击。检测SYN攻击非常的方便,当你在服务器上看到大量的半连接状态时,特别是源IP地址是随机的,基本上可以断定这是一次SYN攻击.在Linux下可以如下命令检测是否被Syn攻击netstat -n -p TCP | grep SYN_RECV
一般较新的TCP/IP协议栈都对这一过程进行修正来防范Syn攻击,修改tcp协议实现。主要方法有SynAttackProtect保护机制、SYN cookies技术、增加最大半连接和缩短超时时间等.
但是不能完全防范syn攻击。
TCP四次握手
1 | A:B 啊,我不想玩了 |
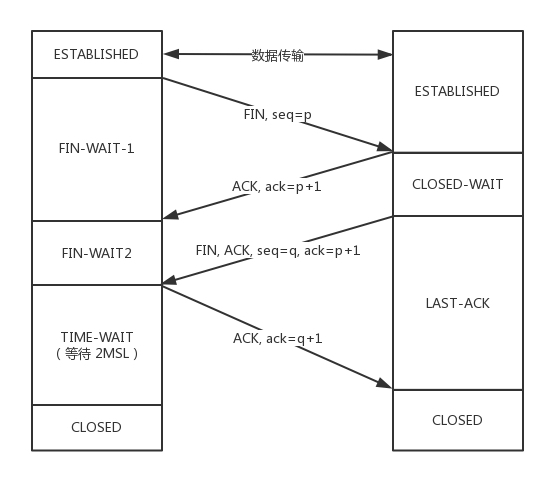
本质的原因是tcp是全双公的,要实现可靠的连接关闭,A发出结束报文FIN,收到B确认后A知道自己没有数据需要发送了,B知道A不再发送数据了,自己也不会接收数据了,但是此时A还是可以接收数据,B也可以发送数据;当B发出FIN报文的时候此时两边才会真正的断开连接,读写分开。
MSL(Maximum Segment Lifetime),最长报文段寿命
TCP允许不同的实现可以设置不同的MSL值。
第一,保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失,站在服务器的角度看来,我已经发送了FIN+ACK报文请求断开了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于是服务器又会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重传的报文,接着给出回应报文,并且会重启2MSL计时器。
第二,防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连接中不会出现旧连接的请求报文。
如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75分钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
累计确认
TCP 如何实现可靠传输?
首先为了保证顺序性,每个包都有一个 ID。在建立连接的时候会商定起始 ID 是什么,然后按照 ID 一个个发送,为了保证不丢包,需要对发送的包都要进行应答,当然,这个应答不是一个一个来的,而是会应答某个之前的 ID,表示都收到了,这种模式成为累计应答或累计确认。
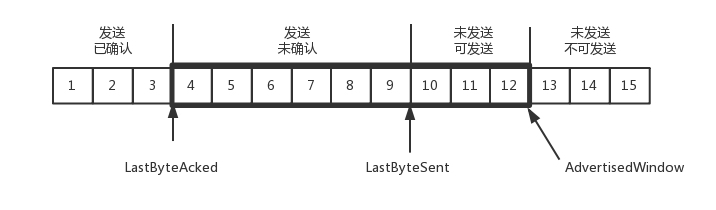
为了记录所有发送的包和接收的包,TCP 需要发送端和接收端分别来缓存这些记录,发送端的缓存里是按照包的 ID 一个个排列,根据处理的情况分成四个部分
- 发送并且确认的
- 发送尚未确认的
- 没有发送等待发送的
- 没有发送并且暂时不会发送的
这里的第三部分和第四部分就属于流量控制的内容
在 TCP 里,接收端会给发送端报一个窗口大小,叫 Advertised window。这个窗口应该等于上面的第二部分加上第三部分,超过这个窗口,接收端做不过来,就不能发送了
于是,发送端要保持下面的数据结构
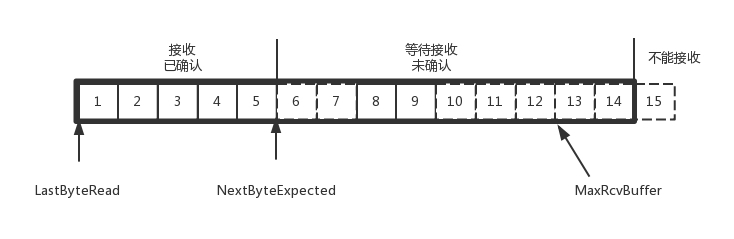
对于接收端来讲,它的缓存里面的内容要简单一些
- 接收并且确认过的
- 还没接收,但是马上就能接收的
- 还没接收,但也无法接收的
顺序问题和丢包问题
结合上面的图看,在发送端,1、2、3 已发送并确认;4、5、6、7、8、9 都是发送了还没确认;10、11、12 是还没发出的;13、14、15 是接收方没有空间,不准备发的。
在接收端来看,1、2、3、4、5 是已经完成 ACK 但是还没读取的;6、7 是等待接收的;8、9 是已经接收还没有 ACK 的。
发送端和接收端当前的状态如下:
1、2、3 没有问题,双方达成了一致
4、5 接收方说 ACK 了,但是发送方还没收到
6、7、8、9 肯定都发了,但是 8、9 已经到了,6、7 没到,出现了乱序,缓存着但是没办法 ACK。
根据这个例子可以知道顺序问题和丢包问题都有可能存在,所以我们先来看确认与重传机制。
假设 4 的确认收到了,5 的 ACK 丢了,6、7 的数据包丢了,该怎么办?
一种方法是超时重试,即对每一个发送了但是没有 ACK 的包设定一个定时器,超过了一定的事件就重新尝试。这个时间必须大于往返时间,但也不宜过长,否则超时时间变长,访问就变慢了。
如果过一段时间,5、6、7 都超时了就会重新发送。接收方发现 5 原来接收过,于是丢弃 5;6 收到了,发送 ACK,要求下一个是 7,7 不幸又丢了。当 7 再次超时的时候,TCP 的策略是超时间隔加倍。每当遇到一次超时重传的时候,都会讲下一次超时时间间隔设为先前值的两倍。
超时重传的机制是超时周期可能相对较长,是否有更快的方式呢?
有一个快速重传的机制,即当接收方接收到一个序号大于期望的报文段时,就检测到了数据流之间的间隔,于是发送三个冗余的 ACK,客户端接收到之后,知道数据报丢失,于是重传丢失的报文段。
例如,接收方发现 6、8、9 都接收了,但是 7 没来,所以肯定丢了,于是发送三个 6 的 ACK,要求下一个是 7。客户端接收到 3 个,就会发现 7 的确又丢了,不等超时,马上重发。
TCP 为什么是可靠连接
- 通过 TCP 连接传输的数据无差错,不丢失,不重复,且按顺序到达。
- TCP 报文头里面的序号能使 TCP 的数据按序到达
- 报文头里面的确认序号能保证不丢包,累计确认及超时重传机制
- TCP 拥有流量控制及拥塞控制的机制
TCP 和 UDP 的区别
- TCP 是面向连接的,UDP 是面向无连接的
- UDP程序结构较简单
- TCP 是面向字节流的,UDP 是基于数据报的
- TCP 保证数据正确性,UDP 可能丢包
- TCP 保证数据顺序,UDP 不保证
- TCP 有拥塞控制,流量控制
什么是面向连接,什么是面向无连接
在互通之前,面向连接的协议会先建立连接,如 TCP 有三次握手,而 UDP 不会
TCP 的顺序问题,丢包问题,流量控制都是通过滑动窗口来解决的
拥塞控制时通过拥塞窗口来解决的
JAVA死锁案例
1 | public class DeadLockTest |
死锁的根本原因1)是多个线程涉及到多个锁,这些锁存在着交叉,所以可能会导致了一个锁依赖的闭环;2)默认的锁申请操作是阻塞的。所以要避免死锁,就要在一遇到多个对象锁交叉的情况,就要仔细审查这几个对象的类中的所有方法,是否存在着导致锁依赖的环路的可能性。要采取各种方法来杜绝这种可能性。
JAVA锁总结:
- JAVA锁整体态势
- 一. synchronized
- 二. 对象锁、类锁、私有锁
- 三. ReentrantLock
- 四. ReentrantReadWriteLock
- 五. CAS
JAVA 锁整体:
在Java中通常实现锁有两种方式,一种是synchronized关键字,另一种是Lock。二者其实并没有什么必然联系,但是各有各的特点,在使用中可以进行取舍的使用。首先我们先对比下两者。
实现:
首先最大的不同:synchronized是基于JVM层面实现的,而Lock是基于JDK层面实现的。曾经反复的找过synchronized的实现,可惜最终无果。但Lock却是基于JDK实现的,我们可以通过阅读JDK的源码来理解Lock的实现。
使用:
对于使用者的直观体验上Lock是比较复杂的,需要lock和realse,如果忘记释放锁就会产生死锁的问题,所以,通常需要在finally中进行锁的释放。但是synchronized的使用十分简单,只需要对自己的方法或者关注的同步对象或类使用synchronized关键字即可。但是对于锁的粒度控制比较粗,同时对于实现一些锁的状态的转移比较困难。例如:
特点:
| tips | synchronized | Lock |
|---|---|---|
| 锁获取超时 | 不支持 | 支持 |
| 获取锁响应中断 | 不支持 | 支持 |
优化:
在JDK1.5之后synchronized引入了偏向锁,轻量级锁和重量级锁,从而大大的提高了synchronized的性能,同时对于synchronized的优化也在继续进行。期待有一天能更简单的使用java的锁。
在以前不了解Lock的时候,感觉Lock使用实在是太复杂,但是了解了它的实现之后就被深深吸引了。
Lock的实现主要有ReentrantLock、ReadLock和WriteLock,后两者接触的不多,所以简单分析一下ReentrantLock的实现和运行机制。
ReentrantLock类在java.util.concurrent.locks包中,它的上一级的包java.util.concurrent主要是常用的并发控制类.
synchronized
1.6之前,synchronized是重量级锁,效率比较低下。
1.6开始,进行了很多优化,如偏向锁,轻量级锁,自旋锁,适应性自旋锁,锁销除,锁粗化等技术减少锁操作的开销。
synchronized同步锁包括4中状态: 无锁,偏向锁,轻量级所,重量级锁,会随着竞争情况逐渐升级。synchronized同步锁可以升级,但是不可以降级(也有说条件非常苛刻),目的是为了提高获取锁和释放锁的效率。
synchronized的底层原理:
synchronized修饰的代码块
从字节码中可以看到,使用monitorenter和monitorexit指令,其中monitorenter指令指向同步代码块的开始位置,monitorexit指向结束位置。
synchronized修饰方法:
同步方法中包含ACC_SYINCHRONIZED标记符,该标记符指明该方法是一个同步方法,从而执行相应的同步调用。
它的修饰对象有几种:
- 修饰一个类,其作用的范围是synchronized后面括号括起来的部分, 作用的对象是这个类的所有对象。
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法, 作用的对象是调用这个方法的对象;
- 修改一个静态的方法,其作用的范围是整个静态方法, 作用的对象是这个类的所有对象;
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码, 作用的对象是调用这个代码块的对象;
对象锁,类锁,私有锁
对象锁:使用 synchronized 修饰非静态的方法以及 synchronized(this) 同步代码块使用的锁是对象锁。
类锁:使用 synchronized 修饰静态的方法以及 synchronized(class) 同步代码块使用的锁是类锁。
私有锁:在类内部声明一个私有属性如private Object lock,在需要加锁的同步块使用 synchronized(lock)
它们的特性:
- 对象锁具有可重入性。
- 当一个线程获得了某个对象的对象锁,则该线程仍然可以调用其他任何需要该对象锁的 synchronized 方法或 synchronized(this) 同步代码块。
- 当一个线程访问某个对象的一个 synchronized(this) 同步代码块时,其他线程对该对象中所有其它 synchronized(this) 同步代码块的访问将被阻塞,因为访问的是同一个对象锁。
- 每个类只有一个类锁,但是类可以实例化成对象,因此每一个对象对应一个对象锁。
- 类锁和对象锁不会产生竞争。
- 私有锁和对象锁也不会产生竞争。
- 使用私有锁可以减小锁的细粒度,减少由锁产生的开销。
私有锁实现等待/通知机制
1 | Object lock = new Object(); |
ReentrantLock
ReentrantLock 是一个独占/排他锁。相对于 synchronized,它更加灵活。但是需要自己写出加锁和解锁的过程。它的灵活性在于它拥有很多特性。
ReentrantLock 需要显示地进行释放锁。特别是在程序异常时,synchronized 会自动释放锁,而 ReentrantLock 并不会自动释放锁,所以必须在 finally 中进行释放锁。
它的特性:
- 公平性:支持公平锁和非公平锁。默认使用了非公平锁。
- 可重入
- 可中断:相对于 synchronized,它是可中断的锁,能够对中断作出响应。
- 超时机制:超时后不能获得锁,因此不会造成死锁。
ReentrantLock 是很多类的基础,例如 ConcurrentHashMap 内部使用的 Segment 就是继承 ReentrantLock,CopyOnWriteArrayList 也使用了 ReentrantLock。
ReentrantReadWriteLock
它拥有读锁(ReadLock)和写锁(WriteLock),读锁是一个共享锁,写锁是一个排他锁。
它的特性:
- 公平性:支持公平锁和非公平锁。默认使用了非公平锁。
- 可重入:读线程在获取读锁之后能够再次获取读锁。写线程在获取写锁之后能够再次获取写锁,同时也可以获取读锁(锁降级)。
- 锁降级:先获取写锁,再获取读锁,然后再释放写锁的过程。锁降级是为了保证数据的可见性。
CAS
上面提到的 ReentrantLock、ReentrantReadWriteLock 都是基于 AbstractQueuedSynchronizer (AQS),而 AQS 又是基于 CAS。CAS 的全称是 Compare And Swap(比较与交换),它是一种无锁算法。
synchronized、Lock 都采用了悲观锁的机制,而 CAS 是一种乐观锁的实现。
CAS 的特性:
- 通过调用 JNI 的代码实现
- 非阻塞算法
- 非独占锁
CAS 存在的问题:
ABA
因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。循环时间长开销大
1
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
只能保证一个共享变量的原子操作
1
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
JAVA快速失败和安全失败
快速失败(fail—fast)
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
注意:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
场景: java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)。
安全失败(fail—safe)
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景: java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
MYSQL
ACID
事务(Transaction)及其ACID属性
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
- 原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持#。
事务隔离级别:
1、DEFAULT
默认隔离级别,每种数据库支持的事务隔离级别不一样,如果Spring配置事务时将isolation设置为这个值的话,那么将使用底层数据库的默认事务隔离级别。顺便说一句,如果使用的MySQL,可以使用”select @@tx_isolation“来查看默认的事务隔离级别
2、READ_UNCOMMITTED
读未提交,即能够读取到没有被提交的数据,所以很明显这个级别的隔离机制无法解决脏读、不可重复读、幻读中的任何一种,因此很少使用
3、READ_COMMITED
读已提交,即能够读到那些已经提交的数据,自然能够防止脏读,但是无法限制不可重复读和幻读
4、REPEATABLE_READ
重复读取,即在数据读出来之后加锁,类似”select * from XXX for update”,明确数据读取出来就是为了更新用的,所以要加一把锁,防止别人修改它。REPEATABLE_READ的意思也类似,读取了一条数据,这个事务不结束,别的事务就不可以改这条记录,这样就解决了脏读、不可重复读的问题,但是幻读的问题还是无法解决
5、SERLALIZABLE
串行化,最高的事务隔离级别,不管多少事务,挨个运行完一个事务的所有子事务之后才可以执行另外一个事务里面的所有子事务,这样就解决了脏读、不可重复读和幻读的问题了
网上专门有图用表格的形式列出了事务隔离级别解决的并发问题:
并发事务处理带来的问题
相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持更多的用户。但并发事务处理也会带来一些问题,主要包括以下几种情况。
更新丢失(Lost Update):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更 新覆盖了由其他事务所做的更新。例如,两个编辑人员制作了同一文档的电子副本。每个编辑人员独立地更改其副本,然后保存更改后的副本,这样就覆盖了原始文 档。最后保存其更改副本的编辑人员覆盖另一个编辑人员所做的更改。如果在一个编辑人员完成并提交事务之前,另一个编辑人员不能访问同一文件,则可避免此问 题。
脏读(Dirty Reads):一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加 控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做”脏读”。
不可重复读(Non-Repeatable Reads):一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
据库事务原子性、一致性是怎样实现的
这个问题的有趣之处,不在于问题本身(“原子性、一致性的实现机制是什么”),而在于回答者的分歧反映出来的另外一个问题:原子性和一致性之间的关系是什么?
他正确地指出了,为了保证事务操作的原子性,必须实现基于日志的REDO/UNDO机制。但这个答案仍然是不完整的,因为原子性并不能够完全保证一致性。
按照我个人的理解,在事务处理的ACID属性中,一致性是最基本的属性,其它的三个属性都为了保证一致性而存在的。
首先回顾一下一致性的定义。所谓一致性,指的是数据处于一种有意义的状态,这种状态是语义上的而不是语法上的。最常见的例子是转帐。例如从帐户A转一笔钱到帐户B上,如果帐户A上的钱减少了,而帐户B上的钱却没有增加,那么我们认为此时数据处于不一致的状态。
在数据库实现的场景中,一致性可以分为数据库外部的一致性和数据库内部的一致性。前者由外部应用的编码来保证,即某个应用在执行转帐的数据库操作时,必须在同一个事务内部调用对帐户A和帐户B的操作。如果在这个层次出现错误,这不是数据库本身能够解决的,也不属于我们需要讨论的范围。后者由数据库来保证,即在同一个事务内部的一组操作必须全部执行成功(或者全部失败)。这就是事务处理的原子性。
为了实现原子性,需要通过日志:将所有对数据的更新操作都写入日志,如果一个事务中的一部分操作已经成功,但以后的操作,由于断电/系统崩溃/其它的软硬件错误而无法继续,则通过回溯日志,将已经执行成功的操作撤销,从而达到“全部操作失败”的目的。最常见的场景是,数据库系统崩溃后重启,此时数据库处于不一致的状态,必须先执行一个crash recovery的过程:读取日志进行REDO(重演将所有已经执行成功但尚未写入到磁盘的操作,保证持久性),再对所有到崩溃时尚未成功提交的事务进行UNDO(撤销所有执行了一部分但尚未提交的操作,保证原子性)。crash recovery结束后,数据库恢复到一致性状态,可以继续被使用。
日志的管理和重演是数据库实现中最复杂的部分之一。如果涉及到并行处理和分布式系统(日志的复制和重演是数据库高可用性的基础),会比上述场景还要复杂得多。
但是,原子性并不能完全保证一致性。在多个事务并行进行的情况下,即使保证了每一个事务的原子性,仍然可能导致数据不一致的结果。例如,事务1需要将100元转入帐号A:先读取帐号A的值,然后在这个值上加上100。但是,在这两个操作之间,另一个事务2修改了帐号A的值,为它增加了100元。那么最后的结果应该是A增加了200元。但事实上, 事务1最终完成后,帐号A只增加了100元,因为事务2的修改结果被事务1覆盖掉了。
为了保证并发情况下的一致性,引入了隔离性,即保证每一个事务能够看到的数据总是一致的,就好象其它并发事务并不存在一样。用术语来说,就是多个事务并发执行后的状态,和它们串行执行后的状态是等价的。怎样实现隔离性,已经有很多人回答过了,原则上无非是两种类型的锁:
一种是悲观锁,即当前事务将所有涉及操作的对象加锁,操作完成后释放给其它对象使用。为了尽可能提高性能,发明了各种粒度(数据库级/表级/行级……)/各种性质(共享锁/排他锁/共享意向锁/排他意向锁/共享排他意向锁……)的锁。为了解决死锁问题,又发明了两阶段锁协议/死锁检测等一系列的技术。
一种是乐观锁,即不同的事务可以同时看到同一对象(一般是数据行)的不同历史版本。如果有两个事务同时修改了同一数据行,那么在较晚的事务提交时进行冲突检测。实现也有两种,一种是通过日志UNDO的方式来获取数据行的历史版本,一种是简单地在内存中保存同一数据行的多个历史版本,通过时间戳来区分。
锁也是数据库实现中最复杂的部分之一。同样,如果涉及到分布式系统(分布式锁和两阶段提交是分布式事务的基础),会比上述场景还要复杂得多。
超卖问题
- 数据库解决
1 | update table set a=a-1 where a>=1 and id =x ,行锁 |
平衡二叉树:
它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。这个方案很好的解决了二叉查找树退化成链表的问题,把插入,查找,删除的时间复杂度最好情况和最坏情况都维持在O(logN)。但是频繁旋转会使插入和删除牺牲掉O(logN)左右的时间,不过相对二叉查找树来说,时间上稳定了很多。
平衡二叉树是在构造二叉排序树的过程中,每当插入一个新结点时,首先检查是否因插入新结点而破坏了二叉排序树的平衡性,若是,则找出其中的最小不平衡子树,在保持二叉排序树特性的前提下,调整最小不平衡子树中各结点之间的链接关系,进行相应的旋转,使之成为新的平衡子树。
红黑树:
一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是red或black. 通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍.它是一种弱平衡二叉树(由于是弱平衡,可以推出,相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数变少,所以对于搜索,插入,删除操作多的情况下,我们就用红黑树.每条路径都包含相同的黑节点.从而保证了红黑树的查找、插入、删除的时间复杂度最坏为O(log n)。
应用
- 广泛用于C++的STL中,map和set都是用红黑树实现的.
- 著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间.
- IO多路复用epoll的实现采用红黑树组织管理sockfd,以支持快速的增删改查.
- ngnix中,用红黑树管理timer,因为红黑树是有序的,可以很快的得到距离当前最小的定时器.
- java中TreeMap的实现.
性质:
性质1. 节点是红色或黑色。
性质2. 根节点是黑色。
性质3 每个叶节点(NIL节点,空节点)是黑色的。
性质4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
二叉查找树
二叉树的提出其实主要就是为了提高查找效率,比如我们常用的 HashMap 在处理哈希冲突严重时,拉链过长导致查找效率降低,就引入了红黑树。
我们知道,二分查找可以缩短查找的时间,但是它要求 查找的数据必须是有序的。每次查找、操作时都要维护一个有序的数据集,于是有了二叉查找树这个概念。
二叉查找树(又叫二叉排序树),它是具有下列性质的二叉树:
- 若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;
- 左、右子树也分别为二叉排序树。
局限性:
一个二叉查找树是由n个节点随机构成,所以,对于某些情况,二叉查找树会退化成一个有n个节点的线性链.
AVL树
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,它是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1).不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此我们可以知道AVL树适合用于插入删除次数比较少,但查找多的情况。
由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树.当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树.
B+树和B树
B树:
还是直接看图比较清楚,图中所示,B树事实上是一种平衡的多叉查找树,也就是说最多可以开m个叉(m>=2),我们称之为m阶b树,为了体现本博客的良心之处,不同于其他地方都能看到2阶B树,

总的来说,m阶B树满足以下条件:
- 每个节点至多可以拥有m棵子树。
- 根节点,只有至少有2个节点(要么极端情况,就是一棵树就一个根节点,单细胞生物,即是根,也是叶,也是树)。
- 非根非叶的节点至少有的Ceil(m/2)个子树(Ceil表示向上取整,图中5阶B树,每个节点至少有3个子树,也就是至少有3个叉)。
- 非叶节点中的信息包括[n,A0,K1,A1,K2,A2,…,Kn,An],,其中n表示该节点中保存的关键字个数,K为关键字且Ki<Ki+1,A为指向子树根节点的指针。
- 从根到叶子的每一条路径都有相同的长度,也就是说,叶子节在相同的层,并且这些节点不带信息,实际上这些节点就表示找不到指定的值,也就是指向这些节点的指针为空。
B树的查询过程和二叉排序树比较类似,从根节点依次比较每个结点,因为每个节点中的关键字和左右子树都是有序的,所以只要比较节点中的关键字,或者沿着指针就能很快地找到指定的关键字,如果查找失败,则会返回叶子节点,即空指针。
例如查询图中字母表中的K:
- 从根节点P开始,K的位置在P之前,进入左侧指针。
- 左子树中,依次比较C、F、J、M,发现K在J和M之间。
- 沿着J和M之间的指针,继续访问子树,并依次进行比较,发现第一个关键字K即为指定查找的值。
B树的特点可以总结为如下:
- 关键字集合分布在整颗树中。
- 任何一个关键字出现且只出现在一个节点中。
- 搜索有可能在非叶子节点结束。
- 其搜索性能等价于在关键字集合内做一次二分查找。
- B树在插入删除新的数据记录会破坏B-Tree的性质,因为在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质。
B+树:
作为B树的加强版,B+树与B树的差异在于
- 有n棵子树的节点含有n个关键字(也有认为是n-1个关键字)。
- 所有的关键字全部存储在叶子节点上,且叶子节点本身根据关键字自小而大顺序连接。
- 非叶子节点可以看成索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字。
B+树的查找过程,与B树类似,只不过查找时,如果在非叶子节点上的关键字等于给定值,并不终止,而是继续沿着指针直到叶子节点位置。因此在B+树,不管查找成功与否,每次查找都是走了一条从根到叶子节点的路径。
B+树的特性如下:
- 所有关键字都存储在叶子节上,且链表中的关键字恰好是有序的。
- 不可能非叶子节点命中返回。
- 非叶子节点相当于叶子节点的索引,叶子节点相当于是存储(关键字)数据的数据层。
- 更适合文件索引系统。
带有顺序访问指针的B+Tree
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
MySQL为什么使用B树(B+树)
红黑树等数据结构也可以用来实现索引,但是文件系统以及数据库系统普遍采用B树或者B+树,这一节将结合计算机组成原理相关知识讨论B-/+Tree作为索引的理论基础。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。下面先介绍内存和磁盘存取原理,然后再结合这些原理分析B-/+Tree作为索引的效率。
B-/+Tree索引的性能分析
到这里终于可以分析B-/+Tree索引的性能了。
上文说过一般使用磁盘I/O次数评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。(h表示树的高度 & 出度d表示的是树的度,即树中各个节点的度的最大值)
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
上文还说过,B+Tree更适合外存索引,原因和内节点出度d有关。从上面分析可以看到,d越大索引的性能越好,而出度的上限取决于节点内key和data的大小:
dmax=floor(pagesize/(keysize+datasize+pointsize))dmax=floor(pagesize/(keysize+datasize+pointsize))
floor表示向下取整。由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能
MySQL索引实现
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
MyISAM索引实现
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图:

这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:

同样也是一棵B+树,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。

上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,上图为定义在Col3上的一个辅助索引:

这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一棵B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
添加索引
ALTER my_table ADD [UNIQUE] INDEX my_index(my_text);
CREATE INDEX my_index ON my_table(my_text);
操作系统
死锁
当然死锁的产生是必须要满足一些特定条件的:
1.互斥条件:进程对于所分配到的资源具有排它性,即一个资源只能被一个进程占用,直到被该进程释放
2.请求和保持条件:一个进程因请求被占用资源而发生阻塞时,对已获得的资源保持不放。
3.不剥夺条件:任何一个资源在没被该进程释放之前,任何其他进程都无法对他剥夺占用
4.循环等待条件:当发生死锁时,所等待的进程必定会形成一个环路(类似于死循环),造成永久阻塞。
进程间通信
- 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
- 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
- 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
线程间通信:
由于多线程共享地址空间和数据空间,所以多个线程间的通信是一个线程的数据可以直接提供给其他线程使用,而不必通过操作系统(也就是内核的调度)。
同步与互斥
信号量:那是多线程同步用的,一个线程完成了某一个动作就通过信号告诉别的线程,别的线程再进行某些动作。
互斥量:这是多线程互斥用的,比如说,一个线程占用了某一个资源,那么别的线程就无法访问,知道这个线程离开,其他的线程才开始可以利用这个资源。
信号量与互斥量之间的区别:
互斥量用于线程的互斥,信号线用于线程的同步。 这是互斥量和信号量的根本区别,也就是互斥和同步之间的区别。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源
互斥量值只能为0/1,信号量值可以为非负整数。
也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量是,也可以完成一个资源的互斥访问。
互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
#clone和new的区别:
(1)在java中clone()与new都能创建对象。
(2)clone()不会调用构造方法;new会调用构造方法。
(3)clone()能快速创建一个已有对象的副本,即创建对象并且将已有对象中所有属性值克隆;new只能在JVM中申请一个空的内存区域,对象的属性值要通过构造方法赋值。
注意:
(1)使用clone()类必须实现java.lang.Cloneable接口并重写Object类的clone()方法,如果没有实现Cloneable()接口将会抛出CloneNotSupportedException异常。(此类实现java.lang.Cloneable接口,指示Object.clone()方法可以合法的对该类实例进行按字段复制。)
(2)默认的Object.clone()方法是浅拷贝,创建好对象的副本然后通过“赋值”拷贝内容,如果类包含引用类型成员变量,那么原始对象和克隆对象的引用类型成员变量将指向相同的引用内容。
面试题:什么是浅拷贝?什么是深拷贝?
“浅拷贝”:默认的Object.clone()方法,对于引用类型成员变量拷贝只是拷贝“值”即地址,没有在堆中开辟新的内存空间。
“深拷贝”:重写clone()方法,对于引用类型成员变量,重新在堆中开辟新的内存空间。
java.lang包【Object类】
基本描述:
(1)Object类位于java.lang包中,java.lang包包含着Java最基础和核心的类,在编译时会自动导入;
(2)Object类是所有Java类的祖先。每个类都使用 Object 作为超类。所有对象(包括数组)都实现这个类的方法。可以使用类型为Object的变量指向任意类型的对象
Object类中的方法:
hashCode()方法:
· 在程序运行过程中,同一个对象多次调用hashCode()方法应该返回相同的值。
· 当两个对象通过equals()方法比较返回true时,则两个对象的hashCode()方法返回相等的值。
· 对象用作equals()方法比较标准的Field,都应该用来计算hashCode值。
equals
clone()方法:快速创建一个已有对象的副本
第一:Object类的clone()方法是一个native方法,native方法的效率一般来说都是远高于Java中的非native方法。这也解释了为什么要用Object中clone()方法而不是先new一个类,然后把原始对象中的信息复制到新对象中,虽然这也实现了clone功能。
第二:Object类中的 clone()方法被protected修饰符修饰。这也意味着如果要应用 clone()方 法,必须继承Object类。
第三:Object.clone()方法返回一个Object对象。我们必须进行强制类型转换才能得到我们需要的类型。
克隆的步骤:1:创建一个对象; 2:将原有对象的数据导入到新创建的数据中。
clone方法首先会判对象是否实现了Cloneable接口,若无则抛出CloneNotSupportedException, 最后会调用internalClone. intervalClone是一个native方法,一般来说native方法的执行效率高于非native方法
toString()方法:
toString方法会返回一个“以文本方式表示”此对象的字符串。结果应是一个简明但易于读懂的信息表达式。建议所有子类都重写此方法。Object类的toString方法返回一个字符串,该字符串由类名(对象是该类的一个实例)、at 标记符“@”和此对象哈希码的无符号十六进制表示组成。finalize()方法:垃圾回收器准备释放内存的时候,会先调用finalize()。
(1). 对象不一定会被回收。
(2).垃圾回收不是析构函数。
(3).垃圾回收只与内存有关。
(4).垃圾回收和finalize()都是靠不住的,只要JVM还没有快到耗尽内存的地步,它是不会浪费时间进行垃圾回收的。
- getClass
- wait
- notify
- notifyall
MySQL中select * for update锁表的问题
页级:引擎 BDB。
表级:引擎 MyISAM , 理解为锁住整个表,可以同时读,写不行
行级:引擎 INNODB , 单独的一行记录加锁
表级,直接锁定整张表,在你锁定期间,其它进程无法对该表进行写操作。如果你是写锁,则其它进程则读也不允许
行级,,仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作。
页级,表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
MySQL 5.1支持对MyISAM和MEMORY表进行表级锁定,对BDB表进行页级锁定,对InnoDB表进行行级锁定。
对WRITE,MySQL使用的表锁定方法原理如下:
如果在表上没有锁,在它上面放一个写锁。
否则,把锁定请求放在写锁定队列中。
对READ,MySQL使用的锁定方法原理如下:
如果在表上没有写锁定,把一个读锁定放在它上面
否则,把锁请求放在读锁定队列中。
InnoDB使用行锁定,BDB使用页锁定。对于这两种存储引擎,都可能存在死锁。这是因为,在SQL语句处理期间,InnoDB自动获得行锁定和BDB获得页锁定,而不是在事务启动时获得。
MySQL中select for update锁表的问题
由于InnoDB预设是Row-Level Lock,所以只有「明确」的指定主键,MySQL才会执行Row lock (只锁住被选取的资料例) ,否则MySQL将会执行Table Lock (将整个资料表单给锁住)。
举个例子:
假设有个表单products ,里面有id跟name二个栏位,id是主键。
例1: (明确指定主键,并且有此笔资料,row lock)
SELECT FROM products WHERE id=’3’ FOR UPDATE;
SELECT * FROM products WHERE id=’3’ and type=1 FOR UPDATE;
例2: (明确指定主键,若查无此笔资料,无lock)
SELECT * FROM products WHERE id=’-1’ FOR UPDATE;
例2: (无主键,table lock)
SELECT * FROM products WHERE name=’Mouse’ FOR UPDATE;
例3: (主键不明确,table lock)
SELECT * FROM products WHERE id<>’3’ FOR UPDATE;
例4: (主键不明确,table lock)
SELECT * FROM products WHERE id LIKE ‘3’ FOR UPDATE;
注1: FOR UPDATE仅适用于InnoDB,且必须在交易区块(BEGIN/COMMIT)中才能生效。
注2: 要测试锁定的状况,可以利用MySQL的Command Mode ,开二个视窗来做测试。
慢查询解决方法
1 | show processlist |
1 | 1,slow_query_log |
explain判断执行状态
HTTPS和HTTP
HTTPS协议 = HTTP协议 + SSL/TLS协议,在HTTPS数据传输的过程中,需要用SSL/TLS对数据进行加密和解密,需要用HTTP对加密后的数据进行传输,由此可以看出HTTPS是由HTTP和SSL/TLS一起合作完成的。
SSL的全称是Secure Sockets Layer,即安全套接层协议,是为网络通信提供安全及数据完整性的一种安全协议。SSL协议在1994年被Netscape发明,后来各个浏览器均支持SSL,其最新的版本是3.0。
TLS的全称是Transport Layer Security,即安全传输层协议,最新版本的TLS(Transport Layer Security,传输层安全协议)是IETF(Internet Engineering Task Force,Internet工程任务组)制定的一种新的协议,它建立在SSL 3.0协议规范之上,是SSL 3.0的后续版本。在TLS与SSL3.0之间存在着显著的差别,主要是它们所支持的加密算法不同,所以TLS与SSL3.0不能互操作。虽然TLS与SSL3.0在加密算法上不同,但是在我们理解HTTPS的过程中,我们可以把SSL和TLS看做是同一个协议。
粘包如何处理
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
出现粘包现象的原因是多方面的,它既可能由发送方造成,也可能由接收方造成。
什么时候需要考虑粘包问题
如果利用tcp每次发送数据,就与对方建立连接,然后双方发送完一段数据后,就关闭连接,这样就不会出现粘包问题(因为只有一种包结构,类似于http协议)。
关闭连接主要是要双方都发送close连接(参考tcp关闭协议)。如:A需要发送一段字符串给B,那么A与B建立连接,然后发送双方都默认好的协议字符如”hello give me sth abour yourself”,然后B收到报文后,就将缓冲区数据接收,然后关闭连接,这样粘包问题不用考虑到,因为大家都知道是发送一段字符。
2 如果发送数据无结构,如文件传输,这样发送方只管发送,接收方只管接收存储就ok,也不用考虑粘包
3 如果双方建立连接,需要在连接后一段时间内发送不同结构数据,如连接后,有好几种结构:
1)”hello give me sth abour yourself”
2)”Don’t give me sth abour yourself”
那这样的话,如果发送方连续发送这个两个包出去,接收方一次接收可能会是”hellogive me sth abour yourselfDon’t give me sth abour yourself”这样接收方就傻了,到底是要干嘛?不知道,因为协议没有规定这么诡异的字符串,所以要处理把它分包,怎么分也需要双方组织一个比较好的包结构,所以一般可能会在头加一个数据长度之类的包,以确保接收。
粘包出现原因
简单得说,在流传输中出现,UDP不会出现粘包,因为它有消息边界
1发送端需要等缓冲区满才发送出去,造成粘包
2接收方不及时接收缓冲区的包,造成多个包接收
具体点:
(1)发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一包数据。若连续几次发送的数据都很少,通常TCP会根据优化算法把这些数据合成一包后一次发送出去,这样接收方就收到了粘包数据。
(2)接收方引起的粘包是由于接收方用户进程不及时接收数据,从而导致粘包现象。这是因为接收方先把收到的数据放在系统接收缓冲区,用户进程从该缓冲区取数据,若下一包数据到达时前一包数据尚未被用户进程取走,则下一包数据放到系统接收缓冲区时就接到前一包数据之后,而用户进程根据预先设定的缓冲区大小从系统接收缓冲区取数据,这样就一次取到了多包数据。
粘包情况有两种,一种是粘在一起的包都是完整的数据包,另一种情况是粘在一起的包有不完整的包。
不是所有的粘包现象都需要处理,若传输的数据为不带结构的连续流数据(如文件传输),则不必把粘连的包分开(简称分包)。但在实际工程应用中,传输的数据一般为带结构的数据,这时就需要做分包处理。
在处理定长结构数据的粘包问题时,分包算法比较简单;在处理不定长结构数据的粘包问题时,分包算法就比较复杂。特别是粘在一起的包有不完整的包的粘包情况,由于一包数据内容被分在了两个连续的接收包中,处理起来难度较大。实际工程应用中应尽量避免出现粘包现象。
为了避免粘包现象,可采取以下几种措施:
(1)对于发送方引起的粘包现象,用户可通过编程设置来避免,TCP提供了强制数据立即传送的操作指令push,TCP软件收到该操作指令后,就立即将本段数据发送出去,而不必等待发送缓冲区满;
(2)对于接收方引起的粘包,则可通过优化程序设计、精简接收进程工作量、提高接收进程优先级等措施,使其及时接收数据,从而尽量避免出现粘包现象;
(3)由接收方控制,将一包数据按结构字段,人为控制分多次接收,然后合并,通过这种手段来避免粘包。
以上提到的三种措施,都有其不足之处。
(1)第一种编程设置方法虽然可以避免发送方引起的粘包,但它关闭了优化算法,降低了网络发送效率,影响应用程序的性能,一般不建议使用。
(2)第二种方法只能减少出现粘包的可能性,但并不能完全避免粘包,当发送频率较高时,或由于网络突发可能使某个时间段数据包到达接收方较快,接收方还是有可能来不及接收,从而导致粘包。
(3)第三种方法虽然避免了粘包,但应用程序的效率较低,对实时应用的场合不适合。
一种比较周全的对策是:接收方创建一预处理线程,对接收到的数据包进行预处理,将粘连的包分开。
TCP无保护消息边界的解决
针对这个问题,一般有3种解决方案:
(1)发送固定长度的消息
(2)把消息的尺寸与消息一块发送
(3)使用特殊标记来区分消息间隔
HTTP 206
206 Partial Content 客户发送了一个带有Range头的get请求,服务器完成了它(http 1.1新)。
JAVA中写时复制(Copy-On-Write)Map实现
1,什么是写时复制(Copy-On-Write)容器?
写时复制是指:在并发访问的情景下,当需要修改JAVA中Containers的元素时,不直接修改该容器,而是先复制一份副本,在副本上进行修改。修改完成之后,将指向原来容器的引用指向新的容器(副本容器)。
2,写时复制带来的影响
①由于不会修改原始容器,只修改副本容器。因此,可以对原始容器进行并发地读。其次,实现了读操作与写操作的分离,读操作发生在原始容器上,写操作发生在副本容器上。
②数据一致性问题:读操作的线程可能不会立即读取到新修改的数据,因为修改操作发生在副本上。但最终修改操作会完成并更新容器,因此这是最终一致性。
3,在JDK中提供了CopyOnWriteArrayList类和CopyOnWriteArraySet类,但是并没有提供CopyOnWriteMap的实现。因此,可以参考CopyOnWriteArrayList自己实现一个CopyOnWriteHashMap
这里主要是实现 在写操作时,如何保证线程安全。
1 | import java.util.Collection; |
从上可以看出,对于put() 和 putAll() 而言,需要加锁。而读操作则不需要,如get(Object key)。这样,当一个线程需要put一个新元素时,它先锁住当前CopyOnWriteMap对象,并复制一个新HashMap,而其他的读线程因为不需要加锁,则可继续访问原来的HashMap。
4,应用场景
CopyOnWrite容器适用于读多写少的场景。因为写操作时,需要复制一个容器,造成内存开销很大,也需要根据实际应用把握初始容器的大小。
不适合于数据的强一致性场合。若要求数据修改之后立即能被读到,则不能用写时复制技术。因为它是最终一致性。
总结:写时复制技术是一种很好的提高并发性的手段。
5,为什么会出现COW?
集合类(ArrayList、HashMap)上的常用操作是:向集合中添加元素、删除元素、遍历集合中的元素然后进行某种操作。当多个线程并发地对一个集合对象执行这些操作时就会引发ConcurrentModificationException,比如线程A在for-each中遍历ArrayList,而线程B同时又在删除ArrayList中的元素,就可能会抛出ConcurrentModificationException,可以在线程A遍历ArrayList时加锁,但由于遍历操作是一种常见的操作,加锁之后会影响程序的性能,因此for-each遍历选择了不对ArrayList加锁而是当有多个线程修改ArrayList时抛出ConcurrentModificationException,因此,这是一种设计上的权衡。
为了应对多线程并发修改这种情况,一种策略就是本文的主题“写时复制”机制;另一种策略是:线程安全的容器类:
ArrayList—>CopyOnWriteArrayList
HashMap—>ConcurrentHashMap
而ConcurrentHashMap并不是从“复制”这个角度来应对多线程并发修改,而是引入了分段锁(JDK7);CAS、锁(JDK11)解决多线程并发修改的问题。